Рынок труда аналитиков и data scientists
Содержание:
- Как стать Data scientist: лучшее обучение
- Что должен знать начинающий Data Scientist?
- Зачем Data Science бизнесу
- Кто такой Data Scientist?
- Что изучает Data Science
- Линейная алгебра
- Какая нужна математика? Если нет матбазы, я безнадёжен?
- Как пройти собеседование специалиста Data Science?
- Признаки важнее, чем модель
- Решаем задачи целиком
- Быть Джуном Мидловичем, Д. С.
- Как различаются роли дата-инженеров и дата-сайентистов
- Основная работа ведётся на удалённом сервере
- Почему мы догоняем, а не опережаем
Как стать Data scientist: лучшее обучение
Следует помнить, что востребованным специалистом не получится стать при самостоятельном изучении всех дисциплин. В любом случае необходимо пройти профессиональные курсы.
Отличный курс для новичков с любым уровнем начальных знаний – «Data scientist» от Skillfaktory. Именно здесь обучение построено таким образом, что на каждом этапе погружения в профессию новичок работает с реальными задачами от партнеров. Каждый полученный кейс входит в портфолио выпускника.
Обучение длится 24 месяца, то есть два семестра по 6 месяцев. За это время новичок достигает уровень Junior с портфолио из 8-и кейсов различных тематик.
Следующие 2 семестра – специализация по выбору. За 12 месяцев студент наполняет свое портфолио еще пятью успешными кейсами. В результате обучения и работы над реальными задачами достигает уровня Middle.

После завершения обучения каждый выпускник обладает знаниями и навыками достигнутого уровня. Может претендовать на соответствующую оплату своего труда.
Особенность обучения на этом курсе в том, что каждый студент в ходе решения задачи может обратиться к куратору. Это помогает оперативно получить ответ на вопрос и поддержку.
За время обучения каждый студент получает 2 года стажа по специальности и профессиональное портфолио уровня Middle. Это значительно экономит время и дает быстрый старт в карьере.
Что должен знать начинающий Data Scientist?
Data scientist должен уметь писать код. Специалист по данным занимается написанием модели для оценки гипотез, аналитики или оценки данных. Этого никак не сделать без знаний основных языков программирования, применяемых в области Data Science. Вам пригодятся знания:
- Java, Hive для работы с Hadoop;
- Python – его основы и понимание того, как работать с ним в анализе данных. Также познакомьтесь с инструментами Matplotlib, Numpy, Scikit, Skipy;
- SQL – для извлечения данных;
- C++ с инструментами BigARTM, Vowpel Wabbit, XGBoost;
- языка R, который пригодится для расчетов статистики.
Математика.
Аналитик данных должен пройти курсы математического анализа, математической статистики, линейной алгебры, а также знать, что такое теория вероятности. Эти знания пригодятся, для того чтобы составлять прогнозы, работать над поиском закономерностей и построением математических моделей.
В математическом анализе вам понадобятся производные, правило дифференцирования сложной функции и градиенты. Описательная статистика, планирование эксперимента и машинное обучение нужно будет изучить в курсе математической статистики
Линейная алгебра нужна для понимания механизмов машинного обучения, там обратите внимание на векторы и пространства, матричные преобразования.
Машинное обучение.
Без него в вашей работе никуда. Машинное обучение нужно для создания новых моделей и переобучения существующих. Также оно связано не только с искусственным интеллектом, но и с генетическими, эволюционными алгоритмами, кластерными задачами и так далее. Благодаря машинному обучению работа Data Scientist с большими объемами данных становится эффективной.
Deep Learning.
Чтобы руководить проектами машинного обучения, вам нужно будет разобраться, как устроены нейронные сети и изучить основы глубокого обучения.
Специфику домена.
Для того чтобы понимать, как работает продукт и создавать подходящую модель, необходимы знания о домене, в котором вы работаете. Data Scientists трудятся во всевозможных отраслях, самыми популярными из которых являются маркетинг, здравоохранение и экономика. Если у вас нет нужных профильных знаний заранее, не переживайте, вы точно приобретете их на проекте.
Английский язык.
Обязательный пункт для любой специальности в ИТ. Английский пригодится вам в работе при общении с зарубежными клиентами и коллегами в многонациональной команде. Также вы столкнетесь с английским во время работы с различными фреймворками и технологиями, и в своем развитии: много технической литературы выпускается только на английском языке.
Если вы уже работаете в Data Science, то наверняка знакомы со всеми этими требованиями. Для опытных аналитиков данных они, конечно же, другие.
Требования к опытному специалисту по данным
Некоторые специалисты описывают успешного Data Scientist как хакера, аналитика, коммуникатора или доверенного консультанта. Давайте разберемся, какие скиллы вам пригодятся.
Кроме hard skills, которые мы описывали выше, вам нужно иметь:
- Опыт разработки моделей машинного и глубинного обучения с фреймворками Hadoop, TensorFlow, Keras, PyTorch, Scikit-Learn, Pytorch, MLLib и другими;
- Глубокие знания одной из областей обучения по прецедентам Machine Learning;
- Опыт работы с SQL и инструментами BigData, как Spark/Hive;
- Опыт работы с инструментами визуализации Pandas, Matplotlib, Seaborne.
Конечно, работа в команде требует развитых гибких навыков для Data Scientist. Давайте рассмотрим, какие навыки вам помогут.
Soft skills для Data Scientist
- Ассоциативное мышление.
- Способность излагать свои мысли так, чтобы их понял другой человек.
- Любопытство для погружения в проблему и дальнейшей работы с гипотезами.
- Умение находить эффективные решения проблем.
- Внимательность.
- Умение работать в команде и находить подход к каждому.
- Умение задавать хорошие вопросы.
- Дотошность.
- Умение визуализировать данные.
С требованиями и навыками разобрались. А теперь давайте узнаем, какие нам пригодятся курсы, видео и материалы, чтобы развиваться в Data Science?

Зачем Data Science бизнесу
Компании используют Data Science вне зависимости от размера бизнеса, показывает статистика Kaggle (профессиональная соцсеть специалистов по работе с данными). А по подсчетам IDC и Hitachi, 78% предприятий подтверждают, что количество анализируемой и используемой информации в последнее время значительно возросло. Бизнес понимает, что неструктурированная информация содержит очень важные для компании знания, способные повлиять на результаты бизнеса, отмечают авторы исследования.

Индустрия 4.0
Роман Нестер — РБК: «Коммерческие данные — это кровь интернета»
Причем это касается самых разных сфер экономики. Вот лишь несколько примеров отраслей, которые используют Data Science для решения своих задач:
- онлайн-торговля и развлекательные сервисы: рекомендательные системы для пользователей;
- здравоохранение: прогнозирование заболеваний и рекомендации по сохранению здоровья;
- логистика: планирование и оптимизация маршрутов доставки;
- digital-реклама: автоматизированное размещение контента и таргетирование;
- финансы: скоринг, обнаружение и предотвращение мошенничества;
- промышленность: предиктивная аналитика для планирования ремонтов и производства;
- недвижимость: поиск и предложение наиболее подходящих покупателю объектов;
- госуправление: прогнозирование занятости и экономической ситуации, борьба с преступностью;
- спорт: отбор перспективных игроков и разработка стратегий игры.
И это лишь самый краткий и поверхностный список использования Data Science. Количество различных кейсов с использованием «науки о данных» увеличивается с каждым годом в геометрической прогрессии.
Каждый интернет-пользователь и просто потребитель ежедневно десятки раз сталкивается с продуктами и решениями, в которых применяются инструменты Data Science. К примеру, аудио-сервис Spotify использует их, чтобы лучше подбирать треки для пользователей в соответствии с их предпочтениями. То же самое можно сказать о предложении фильмов и сериалах на видео-стримингах, таких как Netflix. А в Uber науку о данных рассматривают как инструмент для предиктивной аналитики, прогнозирования спроса, улучшения и автоматизации всех продуктов и клиентского опыта.

Экономика инноваций
Что такое Big Data и почему их называют «новой нефтью»
Конечно, дата-сайентисты не могут в точности предсказать будущее компании и учесть абсолютно все возможные риски. «Все модели неправильные, но некоторые из них полезны», — иронизировал по этому поводу британский статистик Джордж Бокс. Тем не менее, инструменты Data Science служат хорошей поддержкой для компаний, которые хотят принимать более информированные и обоснованные решения о своем будущем.
Кто такой Data Scientist?
Давайте начнем наше знакомство с профессией с области, в которой работают Data Scientists. Data Science – это наука о данных, которая занимается изучением данных, их анализом различными методами и последующим преобразованием данных в полезные знания. Раньше обработать данные человек мог вручную, но сейчас их количество стало настолько огромным, что для обработки часто требуется искусственный интеллект. Поэтому наука активно взаимодействует с машинным обучением, математикой, статистикой и анализом данных.
Нас постоянно окружают результаты работы Data Scientists, например, мы ежедневно смотрим прогноз погоды, реклама предлагает нам определенные товары, авиасервисы прогнозируют стоимость билетов, врачи с помощью программ могут предсказать диагнозы, а голосовые помощники выполняют множество наших просьб. Всем этим и многими другими вещами управляет специалист по данным. Data Scientist – это специалист, который занимается поиском закономерностей в больших массивах данных, анализирует и хранит их. Профессия Data Scientist считается одной из самых высокооплачиваемых и сложных в мире ИТ.
Стоит обратить внимание на то, что Data Science стала неотъемлемой частью будущего. Сейчас ее активно используют в стартапах, IT компаниях, различных бизнесах, чтобы предоставлять наиболее точные данные и прогнозы, быть ближе к пользователю, автоматизировать свои решения и повысить маржинальность бизнеса
Спрос на Data Scientists ежегодно растет. Например, по информации веб-сайта по поиску работы Indeed, за 2019 год вакансий Data Scientists стало на 29% больше.
Data Scientists постоянно ищут паттерны и тренды в огромных наборах данных, используя многообразные тулы, техники и критическое мышление, чтобы найти практическое решение для реальных data-centric проблем. Давайте подробнее поговорим о том, что входит в обязанности специалистов по данным.

Что изучает Data Science
Каждый день человечество генерирует примерно 2,5 квинтиллиона байт различных данных. Они создаются буквально при каждом клике и пролистывании страницы, не говоря уже о просмотре видео и фотографий в онлайн-сервисах и соцсетях.
Наука о данных появилась задолго до того, как их объемы превысили все мыслимые прогнозы. Отсчет принято вести с 1966 года, когда в мире появился Комитет по данным для науки и техники — CODATA. Его создали в рамках Международного совета по науке, который ставил своей целью сбор, оценку, хранение и поиск важнейших данных для решения научных и технических задач. В составе комитета работают ученые, профессора крупных университетов и представители академий наук из нескольких стран, включая Россию.
Сам термин Data Science вошел в обиход в середине 1970-х с подачи датского ученого-информатика Петера Наура. Согласно его определению, эта дисциплина изучает жизненный цикл цифровых данных от появления до использования в других областях знаний. Однако со временем это определение стало более широким и гибким.
Data Science (DS) — междисциплинарная область на стыке статистики, математики, системного анализа и машинного обучения, которая охватывает все этапы работы с данными. Она предполагает исследование и анализ сверхбольших массивов информации и ориентирована в первую очередь на получение практических результатов.
В 2010-х годах объемы данных по экспоненте. Свою роль сыграл целый ряд факторов — от повсеместного распространения мобильного интернета и популярности соцсетей до всеобщей оцифровки сервисов и процессов. В итоге профессия дата-сайентиста быстро превратилась в одну из самых популярных и востребованных. Еще в 2012 году позицию дата-сайентиста журналисты назвали самой привлекательной работой XXI века (The Sexiest Job of the XXI Century).

Объем данных, созданных, собранных и потребленных во всем мире с 2010 по 2024 год (в зеттабайтах)
(Фото: Statista)
Развитие Data Science шло вместе с внедрением технологий Big Data и анализа данных. И хотя эти области часто пересекаются, их не следует путать между собой. Все они предполагают понимание больших массивов информации. Но если аналитика данных отвечает на вопросы о прошлом (например, об изменениях в поведениях клиентов какого-либо интернет-сервиса за последние несколько лет), то Data Science в буквальном смысле смотрит в будущее. Специалисты по DS на основе больших данных могут создавать модели, которые предсказывают, что случится завтра. В том числе и предсказывать спрос на те или иные товары и услуги.
Линейная алгебра
Лично я считаю определение Википедии наиболее полезным: линейная алгебра — это раздел математики, изучающий векторные пространства и линейные отображения между пространствами. Для начала неплохо, однако считаю, что можно немного упростить это определение и сделать его не таким сухим.
Вот несколько наиболее известных примеров использования линейной алгебры в науке о данных на сегодняшний день.
Машинное обучение. Огромное количество методов машинного обучения тесно связано с компонентами линейной алгебры. Некоторые из них: основной компонентный анализ, собственный вектор и регрессия. Они особенно актуальны в работе с высокоразмерными данными, поскольку в них, как правило, присутствуют матрицы.
Моделирование. Если вы хотите каким-либо образом смоделировать поведение, скорее всего, для точных результатов вам понадобятся матрицы — разбить выборки на подгруппы. Здесь пригодится общая матричная алгебра: перестановка, дифференцирование и многое другое.
Оптимизация. Пониманить различия видов применения метода наименьших квадратов невероятно полезно любому специалисту в области данных. Метод наименьших квадратов используют для уменьшения размерности, кластеризации и т. д. — все это имеет значение в оптимизации сетей или прогнозов.
Некоторые из вас, возможно, заметили повторение слов «матрица» и «матрицы», и это не совпадение. Матрицы — большая часть теории общей линейной алгебры. Идеи, используемые для матриц, одинаково применимы к таблицам и фреймам данных — двум фундаментальным структурам, используемым в науке о данных.
Что почитать
(англ.) — хорошее определение в стиле учебника.В чем суть линейной алгебры? (англ.) — большое обсуждение на Quora; обратите особое внимание на первые два ответа, Сэма Лихтенштейна и Дэна Пипони.Что нужно знать о линейной алгебре, чтобы стать хорошим специалистом в области данных? (англ.) — еще одно качественное обсуждение на Quora, ответ Лили Цзян особенно познавательный.Линейная алгебра для специалистов в области данных (англ.) — материал для быстрого погружения в основы
Какая нужна математика? Если нет матбазы, я безнадёжен?

Константин башевой
Аналитик-разработчик в Яндексе и преподаватель курса «Python для анализа данных»
Вопрос про математику неоднозначный. Глубокое знание математики не является ни необходимым, ни достаточным условием. Конечно, тому, кто её знает, будет легче. Но все необходимые знания даются либо на занятиях, либо в дополнительных материалах.
Здесь как в спорте. Есть люди, которые могут без подготовки пробежать марафон. Остальным будет тяжелее, но при достаточной подготовке и они пробегут. Математическая база — это круто, но не критически необходимо.

Дарья Мухина
Продуктовый аналитик Skyeng, консультант курсов аналитики Нетологии
Кажется, что сейчас глубокую математическую базу можно заменить умением гуглить. В интернете огромное количество видео и статей, где можно получить доступно изложенную информацию — и не нужно лезть в университетские учебники. Главное знать, что тебе нужно.
Сейчас важнее навык применять знания в реальной задаче, а не просто обладать ими.
Елена Герасимова
Руководитель направления Data Science в Нетологии
Понятие «профильное техническое или математическое образование» уходит в прошлое. Уверенного в своих умениях и доменных знаниях специалиста из «гуманитарного» вуза не будут сравнивать с выпускником МФТИ по знанию математики — сравнивают по полезности бизнесу для решения задач.
Уже известны десятки рабочих алгоритмов и библиотек, которые способны всю математическую часть брать на себя без участия человека.
Как пройти собеседование специалиста Data Science?
Даже если вы начинающий Data Scientist, вы должны показать, что уже умеете работать с данными и участвовали в соревнованиях, делали что-то сами и принимали участие в хакатонах. Так работодатель поймет, что вы увлечены профессией, готовы развиваться, уже умеете работать в команде и применять знания.
Вы должны будете ответить на вопросы про машинное обучение и статистику.
- Разработка ПО: массивы, хэш-таблицы, всевозможные алгоритмы, связные списки, бинарный поиск, рекурсия.
- Прикладная статистика: теория вероятности, описательная статистика, регрессии, проверка гипотез, байесовский вывод.
- Машинное обучение: метрики классификации, регрессии, выбор статистической модели, переобучение, смещение-дисперсия, сэмплирование, проверка гипотез, модели классификации, модели кластеризации, регрессионные модели.
- Обработка и визуализация данных: организация, профайлинг, визуализация, обработка, стандартизация, нормализация.
- Глубинное обучение.
- Языки программирования.
Записывайте, что вы изучали и приходите уверенным в своих знаниях.
Надеемся, что профессия Data Scientist стала вам ближе и интереснее, а наш материал поможет вам стать лучше и ближе к своей цели. Желаем, успехов! А также приглашаем на собеседование в департамент Data & Analytics ISsoft.
Признаки важнее, чем модель
Линейные модели обычно считаются слишком простыми и не подходящими для реальных задач машинного обучения. Разве можно получить правильный результат, просто линейно увеличивая число признаков? На самом деле — можно.
Более сложные модели, такие как случайный лес, xgboost, SVM и DNN, ищут нелинейные границы в пространстве признаков. Это происходит либо разделением пространства на небольшие участки, либо сопоставлением признаков с пространством большей размерности, где границы выглядят линейно. Проще говоря, процесс построения модели можно рассматривать как подгон прямой линии под вновь сгенерированные точки данных. Поскольку модели не знают истинных значений признаков, они пытаются создать эти новые точки на основе некоторого ядра или путём оптимизации псевдо-функции правдоподобия.
Переход в пространство признаков большей размерности, источник
Звучит довольно сложно, верно? Вот почему такие модели часто называются серыми или чёрными ящиками. С другой стороны, если вы знаете реальные значения признаков, вы можете генерировать новые конструктивные признаки с помощью данных. Процесс генерации, преобразования и предварительной обработки признаков называется конструированием признаков. К его основным подходам относятся поиск стандартного отклонения, дискретизация, агрегирование признаков и так далее.
С правильно спроектированной моделью можно добиться отличных результатов. Линейные алгоритмы обычно лучше интерпретируются — вы можете увидеть значимость сгенерированных признаков и понять по их коэффициентам, насколько достоверна модель. Если коэффициент, который по логике должен быть положительным, оказался отрицательным, — вероятно, что-то не так с моделью, данными или изначальными предположениями.
Решаем задачи целиком
Пол Хиемстра, преподаватель и практик Data Science, даёт три совета тем, кто хочет эффективно изучать науку о данных.
Работайте над проектами целиком. У начинающих дата-сайентистов обычно скромная роль, они отвечают за небольшие кусочки проекта. Эту проблему решает pet-проект, который можно делать параллельно с основной работой. Он поможет помнить о масштабе и не работать над разными этапами по отдельности. Конечно, придётся осваивать и точечные навыки (например, какую-нибудь Python-библиотеку), но потом сразу возвращайтесь к целой задаче.
Как сделать pet-проект: найдите датасет из интересующей вас области и проанализируйте его, например, по методологии CRISP-DM. Описывайте каждое своё действие, а главное — соединяйте шаги между собой. Для этого подойдут сервисы типа Google Colab и Jupyter Notebooks. Подробный отчёт о pet-проекте украсит ваше портфолио.
Найдите хорошего наставника. Обсуждать свою работу с опытным дата-сайентистом — хорошая практика. Так вы прокачаете метакогнитивные навыки, которые необходимы для быстрого разбора сложных проблем. В общении с наставником старайтесь фокусироваться на том, как вы решаете проблему — то есть на подходе и идеях, а не на самом решении (коде, модели, библиотеке). Вопросы «а как…» позволяют максимально раскрыть и перенять опыт.

Найдите единомышленников. Объяснение своих решений другим людям, ответы на их вопросы — прекрасный способ лучше понять собственную работу. Помните незадачливого «препода» из анекдота, который на третий раз уже и сам понял, что говорит, а студенты так и не смогли? Так вот — это не просто шутка. А слушая решения других, пытайтесь в первую очередь выяснить, почему ваш собеседник сделал что-либо (например, выбрал конкретную модель).
Быть Джуном Мидловичем, Д. С.
Успешная работа в Data Science требует сплава знаний из программирования, статистики и консалтинга. Вот примеры задач, которые решает дата-сайентист:
- оценка потребностей заказчика;
- отбор данных для анализа;
- загрузка данных в среду разработки;
- удаление выбросов и обогащение данных;
- выбор и настройка модели;
- интерпретация результатов работы модели.
Настоящий специалист решает задачи согласованно и с учётом их взаимного влияния, а не по отдельности — «сферически в вакууме».

Эти сложные взаимосвязи рабочих задач дата-сайентиста порождают цепочки верхнеуровневых вопросов. Например:
- Как заполнить пропущенные значения в данных, исходя из особенностей бизнеса и потребностей заказчика?
- Какие параметры выбрать у моделей, если пропущенные значения заполнены тем или иным способом?
- Почему модель выдаёт странные результаты: я выбрал не те параметры, не разобрался в отрасли или просто не понял заказчика?
Как различаются роли дата-инженеров и дата-сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны, дата-инженер очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Дата-сайентист создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Если дата-сайентист находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), то дата-инженер создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Он выступает важным звеном между различными участниками: от разработчиков до бизнес-потребителей отчетности. Также помогает повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Дата-сайентист принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.
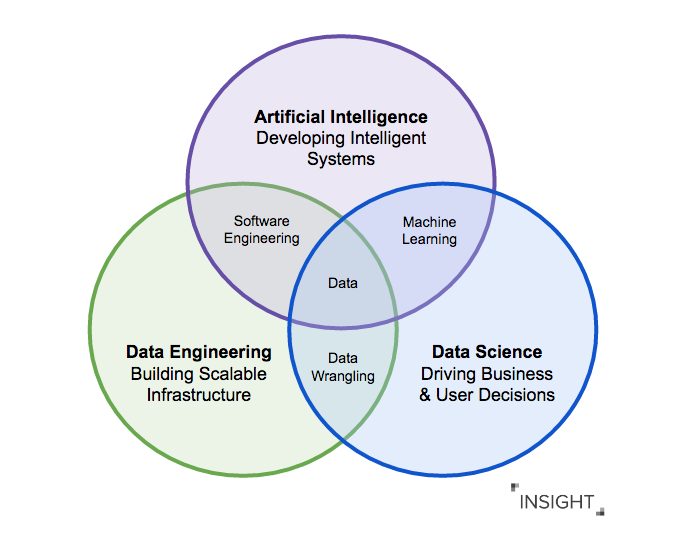
Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными на каждом этапе: от их появления до вывода на дашборд для совета директоров
И важно, чтобы решение об их использовании принималось дата-инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределённом кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надёжных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Основная работа ведётся на удалённом сервере
Большинство людей начинают своё путешествие по Data Science на персональных компьютерах. Однако в реальных проектах зачастую требуется гораздо большая вычислительная мощность, которую не сможет обеспечить ни ноутбук, ни даже игровой ПК. Поэтому исследователи Data Science используют свои компьютеры для доступа к удалённому серверу по SSH (Secure Shell). SSH позволяет безопасно подключиться к вычислительной машине. После установки соединения удалённый сервер можно использовать как командную оболочку вашего компьютера. Поэтому при работе с сервером пригодится знание основных команд для Linux и опыт использования терминала.
Почему мы догоняем, а не опережаем
Часто приходится слышать и отвечать на вопросы о догоняющем развитии отрасли в стране по сравнению с остальным миром
Я считаю, что сейчас важно сконцентрироваться на том, чтобы стать «локальным» лидером в каких-то отдельных типах приложений, областях научных исследований
Это реализуемо: если в России появятся центры притяжения и научные группы определенных специализаций, как прикладного, так и фундаментального плана, если их количество будет расти, то такое лидерство возможно.
Индустрия 4.0
Как работают искусственный интеллект, машинное и глубокое обучение
Например, такой областью могут стать приложения машинного обучения в задачах индустриальной инженерии и управления производством. С одной стороны, в России есть достаточное количество хорошо автоматизированных производств, внедрение на которых автоматизации управления на основе машинного обучения могло бы повысить их эффективность. Есть и компании, кто может на себя взять различного рода инженерные задачи, связанные с интеграцией, внедрением решений в бизнес-процессы. С другой стороны, есть молодые коллективы, которые активно развивают новые методы, их промышленную реализацию и решают конкретные прикладные задачи.
Например, международная летняя школа Сколтеха по машинному обучению SMILES как раз ставит своей задачей привлечь тех, кому интересны более фундаментальные аспекты машинного обучения — потенциально те самые точки локального лидерства. Молодому специалисту трудно ориентироваться в этой огромной научной области, и школа должна помочь понять участникам будущие тренды развития машинного обучения и его приложений.
Спрос на специалистов с конкурентоспособной на мировом уровне подготовкой тоже есть. Не только в России, но и в Белоруссии и Казахстане есть и поддержка науки и научных исследований, и рост автоматизации даже в отраслях так называемой «старой школы», от металлургии до сельского хозяйства. Во всех таких компаниях есть потребность в инженерах с высоким уровнем подготовки — рынок растет и требует людей, возникает возможность работать над интересными задачами. А некоторые специалисты смогут уйти и в предпринимательство, создавая стартапы для развития совершенно новых инструментов и приложений. Все это, разумеется, требует уже глубоких знаний, но и сегодня в России есть места, где такие знания можно получить.

Экономика образования
«Яндекс» инвестирует ₽5 млрд в образование: что делать EdTech-стартапам?
Кроме «Яндекса», который довольно рано осознал недостаток в России учебных программ по машинному обучению и стал вкладываться в эту область еще в 2006-2007 годах, своеобразными ядрами кристаллизации профессионального сообщества стали Mail.ru Group, Ozon и другие компании. Они заинтересованы в привлечении сотрудников с такими компетенциями и понимают, что иногда этих сотрудников бывает проще обучить на своей же площадке. Среди университетов можно отметить Сколтех, НИУ ВШЭ, Университет Иннополис, МФТИ. При этом компании и академическое сообщество активно взаимодействуют: программы сезонных стажировок по специальности есть не только в Сколтехе, но и в других учебных заведениях.