Самые популярные поисковые запросы в яндексе и google
Содержание:
Часть вторая: использование слов «минус»
Для составителя поисковых запросов такие названия брендов, как Hyundai, Volvo или Lamborghini, настоящий подарок: для получения точного запроса достаточно учесть различные варианты написания брендов. Для уникальных названий подобный широкий запрос будет являться полным и релевантным одновременно.
Реальный рынок не всегда бывает так благосклонен к аналитикам: многие названия неоднозначно идентифицируют бренд. Например, ГАЗ может относиться как к отечественной автомобильной группе, так и к топливу, к агрегатному состоянию. Сектор Газа может обозначать как музыкальную группу, так и палестинскую территорию.
Ключевой вопрос, которым задается аналитик при составлении поискового запроса для бренда с неуникальным названием: какова доля релевантных упоминаний в широком запросе? Для оценки чистоты запроса удобно использовать предварительный поиск (кнопка «Показать результаты» внизу) и смотреть долю упоминаний в списке, идентифицирующую искомый бренд. Если при тестировании широкого запроса встречаются иные сущности с тем же названием, доля релевантного потока больше, следует использовать слова «минус», исключающие ненужные объекты из поиска.
Рассмотрим применение блока слов «минус» при составлении полного и релевантного запроса для автомобильного бренда «Форд». Для этого сначала тестируем широкий запрос, состоящий из кириллического и латинского написания бренда.
Предварительная оценка результатов поиска по широкому запросу показывает, что он является полным, но не чистым — встречаются упоминания других объектов с идентичным названием. Так как в данном случае подавляющее большинство упоминаний относится к автомобильному бренду, мы используем подход слов «минус», чтобы исключить отдельные нерелевантные сообщения.
Помимо автомобильного бренда, слово «Форд» (Ford) обозначает распространенную английскую фамилию. В потоке упоминаний встречаются следующие личности с данной фамилией: основатель автомобильного концерна Генри Форд, дизайнер Том Форд, актер Харрисон Форд, режиссер Джон Форд и писатель Мэдокс Форд. Среди перечисленных публичных персон непосредственное отношение к искомому бренду имеет лишь Генри Форд, другие же личности из мира искусства подлежат исключению из поискового запроса.

Чтобы отключить поиск по нерелевантным объектам при создании темы, необходимо добавить их названия (в данном случае имена) в блок слов «минус». Но простое добавление имен Том, Харрисон, Джон и Мэдокс в слова «минус» не совсем корректно.
Мы можем исключить релевантные упоминания типа «Джон Траволта стал новым лицом бренда Форд». Чтобы исключить ошибки такого рода, необходимо сузить расстояние между именем и фамилией исключаемых лиц.
В системе Brand Analytics для этой цели необходимо заключить имя и фамилию в кавычки и после тильды указать максимальное возможное число промежуточных слов и перестановок.
Например, для исключения личности Тома Форда из поиска прописываем словосочетание следующим способом: «Том Форд»~2. Это означает, что между именем и фамилией может быть не более двух слов (например, второе имя/отчество) и перестановок (будут исключены комбинации и Том Форд, и Форд Том).
Стоит отметить, что такая перестраховка при исключении персон требуется в случае распространенных имен (Том, Джон), в более уникальных случаях (Харрисон, Мэдокс) достаточным будет добавить в слова «минус» только имена. Кроме того, каждый запрос необходимо тестировать на варианты написания.

Грамотное использование слов «минус» сохраняет полноту сбора данных и помогает добиваться высокой точности поисковых запросов.
Информация
По информационным запросам Яндекс и Google выглядят примерно одинаково. У российского поисковика есть преимущество в том, что он показывает пресс-портреты по имени и фамилии персоны, IP пользователя и погоду по однословному запросу . Западный поисковик ни одной из этих функций. Google ведет себя адекватнее при запросе, содержащем слово «новости», выдавая вверху выдачи . Яндекс чаще новости на подобные запросы.
|
Действие |
Яндекс |
|
|
Погода в своем городе |
— |
|
|
Погода в каком-либо городе |
||
|
Пресс-портреты |
— |
|
|
Новости |
— |
|
|
Маркет |
glofiish x600 |
— |
|
Финансовые и биржевые показатели |
— |
|
|
Адрес собственного IP |
— |
|
|
мой айпи |
— |
|
|
Карта по адресу |
||
|
Карта города |
Почему важно знать статистику поисковых запросов
Создавая страницы в интернете, их авторы рассчитывают на то, чтобы они стали популярными. Это касается, как сайтов, так и аккаунтов в соцсетях и других сервисов, на которых пользователям предлагается какой-либо контент или услуги.
Существует множество факторов, влияющих на популярность сайтов и страниц. Одним из основных является то, насколько легко ваш ресурс находят пользователи через запросы в поиске. Оптимизация по поисковым запросам играет роль в нескольких ситуациях:
- Создание сайта. Чтобы обеспечить индексацию ресурса по поисковым запросам, начните с определения релевантных и распространённых запросов, через которое максимальное число людей сможет найти ваш сайт.
- Создание страницы на портале. Это может быть персональная страница в соцсети или страница бренда на агрегаторе услуг. В каждом случае страницу необходимо наполнять ключевыми словами. По ним пользователи легче найдут вас.
- Настройка рекламы. Настройка рекламы начинается со сбора семантического ядра. Это список фраз, которые приведут пользователя на ваш сайт. Ключевые слова из семантического ядра учитываются поисковой системой, в рамках которой настраивается реклама. Когда кто-то вводит в строку слова, указанные в вашем семантическом ядре, поисковая система включает ваши страницы в выдачу пользователя. Позиции в ней зависят от ряда факторов — например, поведенческих, о которых мы писали недавно.
В каждом из этих случаев требуется провести сбор и анализ ключевых запросов.
Запуская рекламную кампанию, рекомендуем выбирать сервисы автоматизации. Качественные кампании состоят из множества ключевых слов, управлять ставками которых в режиме нон-стоп почти невозможно. Задачу автоматизации легко решает, например, Оптимизатор Calltouch.
Наши продукты помогают вашему бизнесу оптимизировать расходы на маркетинг Узнать подробнее
Что такое Яндекс Wordstat
Яндекс Wordstat — бесплатный сервис, предназначенный для сбора статистики поисковых запросов в Яндексе. Он помогает рекламодателям и веб-мастерам понять популярность тех или иных ключей, выявить тренды, а также спрос на товары и услуги.
На деле Wordstat отображает прогнозное количество показов ключа в месяц на основе существующей статистики поиска, не включая РСЯ. В списках приводятся как различные вариации исследуемой фразы, так и те, которые наиболее часто ей сопутствуют. На этой основе можно делать выводы о смежных сферах интересов пользователей, которые затем использовать в кампании.
Благодаря сервису у специалиста появляется возможность:
- Собрать основу семантического ядра;
- Ранжировать популярность запросов по регионам;
- По устройствам;
- Выявить сезонность.
А с Calltouch можно анализировать результаты проделанной работы.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Между тем, существует ряд ограничений на работу с сервисом. Так, для качественного парсинга и анализа всех ключевых слов специалисту придётся использовать дополнительное программное обеспечение или плагины. Дело в том, что поиск по статистике Яндекса возможен только в ручном режиме. Процесс отсеивания и сбора ключевых фраз становится рутинным и трудоёмким в связи с невозможностью их загрузки на компьютер стандартными средствами сервиса. Из-за этого сбор семантического ядра через Wordstat не может быть произведён в полном объёме, если не прибегать к сторонним инструментам.
Вместе с этим, составление ядра затрудняется и ограничением по объёму выдачи. Если ваш запрос имеет много вариаций и весьма популярен в различных формах, вы вероятно не сможете проанализировать и использовать их все. Вордстат позволяет просмотреть лишь 2000 строк результата — 40 страниц по 50 фраз. Если за пределами остаются важные низкочастотные ключи, вы с трудом сможете их достать стандартными средствами.
Более того, для пользования Wordstat вы должны войти в Яндекс аккаунт. Уже в процессе работы с сервисом вы рискуете постоянно вводить капчу и даже быть забаненными в случае злоупотребления поиском однотипных запросов. Чтобы продолжать пользоваться сервисом в нормальном режиме, вы можете попробовать вводить слова в разных падежах. Например: вордстат Яндекс, вордстата Яндекса.
Мэйл ру
Стремительно сдающий позиции поисковик, держащийся на плаву исключительно благодаря старомодной части интернета, использующей социальную сеть «одноклассники» и общение на «мой мир». Трудно сказать почему, но мэйл ру не вызывает симпатий пользователей. Может быть, из-за старомодного интерфейса, или из-за слишком навязчивой рекламной компании, заставлявшей устанавливать виджеты поисковика, серьезно замедлявшие работу компьютера.
В результате, все, что связано с данной поисковой системой вычищается и удаляется пользователями просто по привычке. Компания неспешно дрейфует в сторону браузерных игр и мморг стратегий. Кроме поисковика, мэйл ру принадлежит видеосервис «ру туб» с некогда амбициозными планами захвата русскоязычного сектора видеопоиска. Не слишком успешное финансовое управление и устаревшая техническая база привели первый русский поисковик с собственной почтовой системой на грань, когда многие еще помнят эту систему, но мало кто пользуется.

Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Операторы для работы с Wordstat Yandex
1. Оператор кавычки
Поставив запрос в кавычки, мы фиксируем слова, которые есть в запросе. Например, если запрос «лыжные палки» взять в кавычки, то будет показано суммарное число запросов, которое включает следующие варианты:
Порядок слов и окончания могут изменяться.
2. Оператор восклицательный знак
Чтобы зафиксировать нужное нам окончание есть специальный оператор восклицательного знака. Для того чтобы воспользоваться им необходимо перед словом (или словами) поставить восклицательный знак. Таким образом, мы получим нужную словоформу. Например, «!лыжные !палки».
Оператор кавычек и восклицательного знака используются часто и являются самыми ходовыми и востребованными.
3. Оператор квадратные скобки
Оператор [] появился недавно. Он позволяет зафиксировать порядок слов. Многие вебмастера и оптимизаторы хотели его появления и спустя много лет Яндекс их услышал и реализовал. Например, «».
4. Оператор плюс (+)
Ставя плюс перед словом, оно становится обязательным. Это скорее относится к предлогам, поскольку они часто не учитываются. Например, для предлогов «как», «что», «когда», «куда» и т.п. это будет критичным. Например «+как заработать на сайте». Будет обязательно учитывать слово «как». Если мы не поставим плюс, то будут учитываться частотности для запроса «заработать на сайте».
5. Оператор или (|)
Оператор или (|) полезен в тех случаях, когда слово может быть написано на английском или русском. Например, (биткоин|bitcoin).
Программы для упрощённой работы с Wordstat Yandex
Чтобы делать более быстро выгрузки данных из сервиса Яндекс Вордстат использует различные программы. Например, Кейколлектор.
Часть первая: как составлять поисковые запросы
Создание поисковых запросов — это особое искусство. Оно требует высочайшей степени точности: от грамотности его составления зависит объем базы данных, который нам будет доступен. Это еще и творческое видение —зачастую следует погрузиться в среду исследуемого бренда, чтобы выяснить пользовательские ассоциации, жаргонные названия объекта мониторинга.
Идеальный поисковый запрос удовлетворяет одновременно двум критериям:
- полнота — покрывает все упоминания искомого объекта;
- релевантность — в поток не попадают упоминания, которые не относятся к искомому объекту.
Шаг 1. Кириллица и латиница
Стартуем с основного названия бренда. В большинстве случаев нам нужны и кириллическое, и латинское написания.
Рассмотрим на примере автомобильного бренда Mitsubishi. Через запятую указываем 2 варианта написания — Митсубиси (кириллический вариант) и Mitsubishi (на латинице). Запятая в данном случае означает логический знак «или» — таким образом, в наш поток попадают упоминания, где есть хотя бы один из вариантов написания.

Шаг 2. Орфография
На втором шаге для каждого запроса составляем палитру всевозможных вариантов написаний с учетом опечаток пользователей и различных способов транслитерации.
В простых случаях (Милка, Milka) официальное название совпадает с разговорным употреблением слова, но большинство как зарубежных, так и отечественных брендов предполагают не единственный способ написания. Рассмотрим разнообразие опечаток и транслитерации на примере Mitsubishi.
В кириллическом варианте написания Митсубиси различные интерпретации возможны в двух частях слова (выделены жирным шрифтом). Сочетание «тс» зачастую заменяется «тц» или «ц», а вместо «с» в конце слова используют «ш». Для того чтобы не потерять ни один из множества вариантов, удобно использовать следующую матрицу (в строках отражены варианты написания первого сложного сочленения букв «тс», в столбцах — второго).
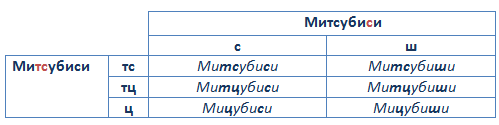
Таким же способом мы подбираем возможные опечатки для латинского варианта. Нетипичное скопление согласных предрасполагает к пропускам букв: сочетание ts по близости звучания иногда заменяется буквами с, tc, z, tz, s, а сочетание sh — s, ch, c. Каждый из запросов по отдельности тестируем в строке поиска (кнопка «Показать результаты») для оценки популярности каждого способа написания. В запрос включаем те варианты, по которым есть поток.

Шаг 3. Жаргонизмы
Кроме опечаток и вариативной транслитерации, пользователи часто используют жаргон в обсуждениях бренда, изменяют слова с помощью сокращения или добавления разнообразных суффиксов.
Например, Митсубиси часто сокращают до Митсу или Митсубы, что в дальнейшем трансформируется в Митсуху и даже Митсубиську. Стоит отметить, что каждый из данных запросов также стоит расширить вариантами написания и проверить в предварительном поиске на частоту упоминаний.

Шаг 4. Связанные объекты
В некоторых случаях название компании прочно ассоциируется с ее первыми лицами, с отдельными продуктами, с известным в народе рекламным слоганом. Если эти объекты имеют отличные от основной торговой марки названия и при этом конкурируют с ней по узнаваемости, их стоит включить в поисковый запрос.
Например, компания Apple прочно ассоциируется со Стивом Джобсом, а слоган «Не тормози — сникерсни» — с шоколадкой Snickers.
В полюбившемся нам примере Mitsubishi важно включить названия основных модельных рядов. Они идентифицируют общую торговую марку, имея при этом уникальные названия Pajero, Outlander и Lancer
Для каждой из дополнительных марок повторяем процедуру шагов 1−3, чтобы учесть разнообразие вариантов написания.

Шаг 5. Уникальные хештеги

Таким образом, даже в самых сложных примерах можно составить поисковый запрос высочайшего уровня полноты. Готовые поисковые запросы также удобно проверять по опорным точкам:
- все ли варианты написания (кириллица/латиница, транслитерация, опечатки) учтены?
- учтены ли жаргонизмы?
- есть ли значимые связанные объекты (персоны, слоганы, продукты)?
- включены ли уникальные хештеги?
Часть третья: использование слов «плюс»
При определенных условиях слова «минус» не подходят. Например:
- Невозможно ограничить список нерелевантных сущностей (по широкому запросу Иванов, помимо главы администрации, в поток попадают бесчисленные персоны с такой же фамилией).
- Невозможно подобрать ключевые слова для идентификации исключаемых объектов (например, для сорта пива «Львовское» по широкому запросу Львовское поиск выдает множество нерелевантных сообщений с соответствующим прилагательным, в каждом случае относящимся к различным ключевым словам: Львовское отделение, Львовское консульство, Львовское издание).
Чтобы выбрать нужный подход («минус» или «плюс»), на этапе тестирования широкого запроса необходимо ответить на ключевой вопрос: «Какова доля релевантных сообщений в предварительном потоке?»
Если нерелевантных объектов в потоке немного и их можно идентифицировать ключевыми словосочетаниями, тогда мы используем подход слов «минус». Если же поток очень грязный, то есть в нем преобладают нерелевантные упоминания, которые нельзя исключить словами «минус», на помощь приходит метод уточнений, или слов «плюс». Рассмотрим их работу на примере еще одного автомобильного бренда «Волга».
Первым шагом тестируем широкий запрос Волга, Volga в предварительном поиске (кнопка «Показать результаты»). Оцениваем поток на чистоту — большая доля упоминаний идентифицирует не искомый бренд, а другие объекты: река Волга, университет ВолГУ, различные местные компании с Волгой в составе названия, деревня Волга, бренды стиральной машины, пианино.

Анализ контекста упоминаний позволяет сделать вывод о том, что подход слов «минус» здесь неуместен: исключение сообщений об одной реке представляется нетривиальной задачей, ведь зачастую в сообщениях не фигурирует слово «река» (на берегу Волги, мост через Волгу, идет по Волге).
Для составления полного и точного запроса необходимо собрать максимальный набор уточняющих слов (слов «плюс»). В нашем примере уточняющие слова — это слова, которые чаще всего употребляются в контексте автомобильного бренда «Волга». Для поиска слов «плюс» также удобно пользоваться предварительным поиском.
В текстах релевантных сообщений ищем характерные слова, идентифицирующие автомобильный бренд. Например, «Волга» с пробегом, за рулем «Волги», «Волга» обогнала «Мерседес».
Оценка контекста позволяет выявить следующие категории слов «плюс», с помощью которых можно создать полный и чистый поисковый запрос.

Включение уточняющих слов в запрос производится через пробел (логический знак «и»), между комбинациями ставится запятая (логический знак «или»). Так ведется поиск всех сообщений, содержащих название бренда хотя бы с одним из уточняющих слов.

Конвертация и калькулятор
Наиболее серьезные различия между поисковыми системами наблюдаются в подсчитывании математических выражений и конвертации из одной меры измерения в другую. Начнем с того, что Яндекс выполняет 4 математических действия сразу в поисковой строке. Как только пользователь ввел, запрос, состоящий из чисел и математических знаков, поисковая строка раскрывается вниз, показывая результат. Google показывает результаты над выдачей.
Кроме четырех математических действий Яндекс не может вычислять ничего: ни корней, ни процентов, ни логарифмов, ни факториалов, ни тригонометрических функций. Это с успехом делает Google. К тому же западный поисковик способен переводить ; из одной системы счисления в другую (например, ).
Примерно одинаково поисковые системы справляются с задачами конвертации: из одной системы мер длины, массы, объема в другую. Яндекс не поддерживает функции конвертации температур из системы Фаренгейта в Цельсиус, или наоборот, и из одной валюты в другую.
|
Действие |
Яндекс |
|
|
Конвертация меры длины |
||
|
Конвертация меры веса |
||
|
Конвертация меры объема |
||
|
Конвертация температуры |
— |
|
|
Конвертация в другую систему счисления |
— |
|
|
— |
||
|
— |
||
|
— |
||
|
Конвертация из арабских цифр в римские |
— |
2009 in roman |
|
Конвертация валюты |
— |
|
|
Курс валют |
dollar euro rate |
|
|
Корень квадратный |
— |
|
|
Корень большей степени |
— |
|
|
Процент |
— |
|
|
Синус, косинус, тангенс, катангенс |
— |
|
|
— |
||
|
— |
||
|
— |
||
|
Факториал |
— |
|
|
Логарифм |
— |
|
|
Десятичный логарифм |
— |
Примеры использования Google Trends
Рассмотрим на небольших примерах, как можно использовать инструментарий Гугл Трендс для анализа поисковых запросов.
Популярность запроса в регионе
Рассматриваем динамику распределения популярности запроса по географическому признаку. Здесь можно использовать более сложную сравнительную фильтрацию: проводить анализ одновременно по нескольким странам, на уровне субрегионов и городов. Уровень интереса по субъектам виден при наведении курсора мыши на область карты.
Конкурентный анализ
Функционал похожих тем и запросов позволяет обнаружить конкурентов бренда, которыми интересуется целевая аудитория. Например, по запросу «Mercedes-Benz» пользователи также ищут «BMW M5» и даже «Нагрудный знак». Данный функционал позволяет, в частности, составить список брендов-конкурентов, использовать информацию о сильных сторонах вашего продукта по сравнению с обобщенными конкурентами на посадочной странице.
Определение формулировки высокочастотного запроса
Еще один инструмент, который можно применять в CEO-продвижении. Позволяет провести терминологический анализ по частоте запросов слов-синонимов. Полезен при сборе семантического ядра и последующей оптимизации сайта.
Определение наиболее популярного продукта в нише
Этот сценарий использует тот же функционал сравнения раздела «Анализ», что и предыдущий. Позволяет эффективно расходовать рекламный бюджет, сделав акцент на самом популярном продукте. Для примера возьмем линейку спортивных тренажеров.
Безусловным лидером оказалась беговая дорожка, на которую в первую очередь следует акцентировать маркетинговый бюджет. Любопытно, что велотренажер и степпер выступают как товары-субституты практически при равном количестве и тренде запросов.
Анализ трендов в YouTube
Очень полезный инструмент для выбора тем, наиболее популярных у целевой аудитории канала.
Видеоконтент все чаще появляется в выдаче Google, в том числе и в виде расширенного сниппета на «нулевой» позиции. Правильный выбор темы и оптимизация видео может принести трафик не только с YouTube, но и из органики.
Выбор горячей темы для статьи, поста или блога
Инструмент полезен не только для частного использования блогерами, следящими за «клубничкой» и «жареными» событиями. Профессиональное SMM-продвижение также требует внимательно следить за сенсациями, поступками медийных персон для привлечения внимания целевой аудитории и создания максимально актуальных постов. Раздел «Популярные запросы» позволит оставаться в тренде основных событий, интересующих пользователей интернета. При клике на стрелку рядом с картинкой, соответствующей запросу, появляется информация о похожих запросах (если они есть) и ссылки на материалы из Google Новостей, включающие запрос.
Минус-слова (оператор «-«)
Чтобы в дальнейшем не чистить семантику от ненужных вхождений ключевых слов, на этапе запросов к Вордстату можно задавать минус-слова.
- Они сэкономят время на чистку (изначальный размер базы будет меньше).
- Сократят вероятность повторного парсинга в частотных нишах (когда на 40-й странице wordstat ключи не заканчиваются, например, имеют частотность 150).
- Покажут уточненный масштаб тематики.
- Уберут слова, не относящиеся к задачам пользователя (Яндекс приводит пример с автомобилем киа и бильярдным кием — «купить киа -!кий»).
- Пример без стоп-слов.
А здесь уже со «стопами» в виде «бесплатно» и «самостоятельно».
Минус-слова можно задавать через запятую (знак «-» повторять каждый раз). Дополнительно к словам можно добавлять операторы: «!», «[]», «+», «кавычки».
Базовые операторы, уточняющие запрос
И Google, и Яндекс предоставляют пользователю возможность искать документ, в котором не содержится определенного слова; документ в котором присутствует любое из слов запроса, и документ, в котором встречается абсолютно точное вхождение запроса. В каждой из поисковых систем за это отвечают различные операторы. Уникальными для Яндекса являются операторы:
- N, в котором N заменяется на число, обозначающее количество слов, которое может разделять в документе слова запроса;
- ! осуществляет поиск без учета морфологии запроса. В американском поисковике Google такой оператор не нужен из-за природы английского языка, слова которого практически не содержат окончаний;
- & и && осуществляют поиск слов, встречающихся в одном предложении и на одной странице соответственно.
Google может похвастаться операторами поиска в определенном числовом интервале (. .) и оператор, заменяющий любое слово (*).
|
Действие |
Яндекс |
|
|
Строго все слова запрос |
||
|
Поиск документа, в котором не содержится слов после знака |
||
|
Ищет любое из слов запроса |
||
|
Ищет точное вхождение запроса |
||
|
Замена любого слова |
— |
|
|
Числовой интервал поиска |
— |
|
|
Слова запроса встречаются в одном предложении |
— |
|
|
Слова запроса находятся на одной странице |
— |
|
|
Слова на расстояние указанного числа слов |
— |
|
|
Поиск без учета морфологии |
— |
Статистика запросов Яндекс
Один из самых популярных сервисов Рунета – Yandex. В 1998 году было начато изучение русскоязычного интернета по месяцам с исследования «НИНИ-индекс». Сегодня статистика ключевых запросов Яндекс доступна всем. Как узнать статистику запросов в Яндексе? Этой цели служит система по продаже контекстной рекламы Яндекс Директ.
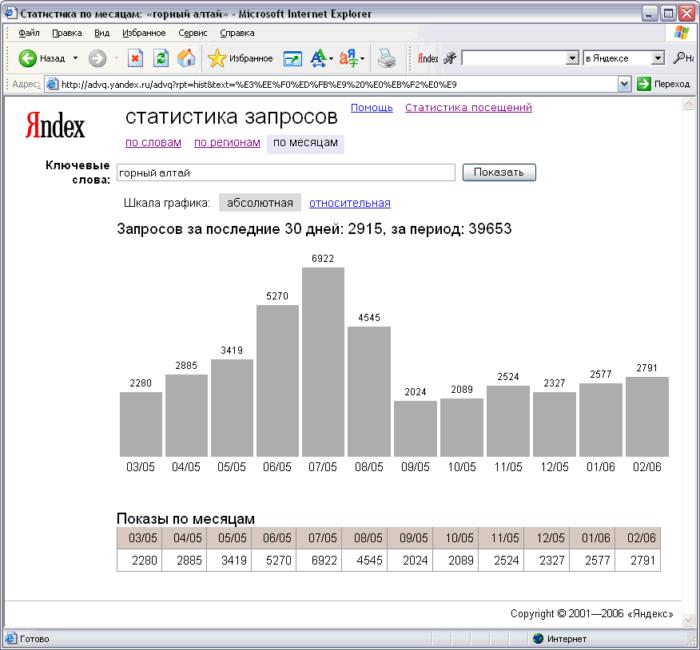 Статистика поисковых запросов Яндекс имеет специализированный сервис wordstat.yandex.ru. Однако он позволяет узнать частотность запросов только в Яндекс Директе. Для подавляющего людей, которых интересует статистика запросов товара – этого хватает.
Статистика поисковых запросов Яндекс имеет специализированный сервис wordstat.yandex.ru. Однако он позволяет узнать частотность запросов только в Яндекс Директе. Для подавляющего людей, которых интересует статистика запросов товара – этого хватает.
Главная страница Яндекс Вордстат имеет поисковую строку для ввода слова или фразы. Статистика поисковых запросов Яндекс не зависит от того, в единственном или множественном числе написана фраза. Словоформы и предлоги Яндекс не учитывает. Если написать слово в кавычках или с восклицательным знаком впереди, то можно узнать именно его частотность. Существуют и другие операторы для более точной работы сервиса. Яндекс Вордстат позволяет узнать:
- прогноз фраз на месяц;
- поисковые запросы по сезонам года, расположенные по алфавиту;
- какие темы популярны у информационных сайтов за определенный период;
- насколько популярна фраза в заданном регионе или по городам.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Как найти популярные ключевые слова в Яндексе
В примере ниже рассмотрим, как находить популярные ключевые фразы, которые чаще спрашиваются и имеют правильную форму. Имея эти данные, их можно проверять по статистике ключевых слов.
Если Вас интересуют конкретные популярные слова в виде “рейтинг запросов в яндексе”, то скорее всего – эти данные в открытом виде, найти будет сложно. Но на самом деле, есть некоторые способы узнать о самых популярных словах. На помощь, могут прийти данные статистики Liveinternet и конечно же Гугл Тренды. Об этих инструментах, мы поговорим чуть ниже.
И кстати! В официальном блоге Яндекса или Твиттере Yandex, иногда публикуются популярные направления, что люди искали чаще всего. Обычно, эти данные предоставляют в виде постера. Например:

…или другой пример – новые слова на поиске, набирающие популярность: