Как закрыть сайт wordpress от индексации поисковиков, урок 76
Содержание:
Пример настройки файла robots.txt
Давайте разберем на примере, как настроить файл robots.txt. Ниже находится пример файла, значение команд из которого будет подробно рассмотрено в статье.
В данном файле мы видим, что от поисковых систем Яндекс и Google закрыты от индексации все документы на сайте, кроме страницы /test.html
Остальные поисковые системы могут индексировать все документы, кроме:
- документов в разделах /personal/ и /help/
- документа по адресу /index.html
- документов, адреса которых включают параметр clear_cache=Y
Последние две команды требуют отдельного внимания.
Командой /index.html закрыт от индексации дубль главной страницы сайта. Как правило, главная страница доступна по двум адресам:
- site.com
- site.com/index.html или site.com/index.php
Если не закрыть второй адрес от индексации, то в поиске может появиться две главных страницы!
Команда Disallow: /*?clear_cache=Y закрывает от индексации все страницы, в адресах которых используется последовательность символов ?clear_cache=Y. Часто различный функционал на сайте, например, сортировки или формы подбора добавляют к адресам страниц различные параметры, из-за чего генерируется множество страниц-дублей. Закрывая дубли с параметрами от индексации, Вы решаете проблему попадания дублей в базу поисковых систем.
Посмотрите, какие страницы необходимо закрывать от индексации, в статье про проведение технического аудита сайта.
Директивы robots.txt
Порядок включения директив:
Для начала стоит сказать о том, какие директивы могут использоваться в файле robots.txt.
User-agent – указание робота, для которого составлен список директив ниже. Обязательная для robots.txt директива, которая указывается в начале файла.
- Основной User-agent поисковой системы Яндекс – Yandex (, которым можно указать отдельные директивы).
- Основной User-agent поисковой системы Google – Googlebot (список роботов Google, которым можно указать отдельные директивы).
- Если список директив указывается для всех возможных User-agent’ов, ставится – «*»
Disallow – директива запрета индексации документов. Можно указывать как каталог, так и часть названия документа, так и полный путь документа.
- При запрете индексации документа путь определяется от корня сайта (красная стрелка на рисунке 1).
- Для запрета индексации документов второго и далее уровней можно указывать полный путь документа, или перед адресом документа указывается знак «*» (синяя стрелка на рисунке 1).
- При запрете индексации каталога также будут запрещены к индексации все страницы, входящие в этот каталог (зеленая стрелка на рисунке 1).
- Можно запрещать для индексации документы, в url которых содержатся определенные символы (розовая стрелка на рисунке 1).
 Рис. 1 Директива Disallow
Рис. 1 Директива Disallow
Allow – директива разрешения индексации документов. Является директивой по умолчанию для всех документов на сайте, если не указано другое.
Используется для открытия к индексации документов (синие стрелки), которые по той или иной причине находятся в каталогах, закрытых от индексации (красные стрелки).
Можно открывать для индексации документы, в url которых содержатся определенные символы (синие стрелки).
Стоит обратить внимание на : «Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно.»
 Рис. 2 Директива Allow
Рис. 2 Директива Allow
Sitemap – директива для указания пути к файлу xml-карты сайта.
Если сайт имеет более 1 карты xml, допустимо указание нескольких путей.
|
User-agent: * Sitemap: http://site.ru/sitemap-1.xml Sitemap: http://site.ru/sitemap-2.xml |
Спецсимволы
- * — означает любую последовательность символов. Добавляется по умолчанию к концу каждой директивы (красная стрелочка на рисунке 3).
- $ — используется для отмены знака «*» на конце директивы (синяя стрелочка на рисунке 3).
- # — знак описания комментариев. Все что указывается справа от этого знака не будет учитываться роботами.

Рис. 3 Спецсимволы
Host – директива указания главного зеркала сайта. Учитывается только роботами Яндекса.
- Данная директива может склеить не только зеркала вида www.site.ru и site.ru но и другие сайты, в robots.txt которых указан соответствующий Host.
- Если зеркало доступно только по защищенному протоколу, указывается адрес с протоколом (https://site.ru). В других случаях протокол не указывается.
- Для настройки главного зеркала в поисковой системе Google используется функция «Настройки сайта» в Google Search Console.
Crawl-delay – директива указания минимального времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Учитывается только роботами Яндекса. Директива используется, чтоб роботы поисковых систем не перегружали сайт.
Для ограничения времени между окончанием загрузки одной страницы и началом загрузки следующей в поисковой системе Google используется функция «Настройки сайта» в Google Search Console
Clean-param – директива используется для удаления параметров из url-адресов сайта. Учитывается только роботами Яндекса.
- Может использоваться для удаления меток отслеживания, фильтров, идентификаторов сессий и других параметров.
- Для правильной обработки меток роботами Google используется функция «Параметры URL» в Google Search Console.
 Рис. 4 Clean-param
Рис. 4 Clean-param
Noindex
Теперь речь пойдёт о теге noidex. Этот тег придумал небезызвестный всем нам поисковик Яндекс.
Он раньше не распознавал тег rel=”nofollow”, поэтому все сеошники пользовались именно тегом noidex для закрытия своих ссылок от индексации Яндекса.
Но вскоре ситуация изменилась — Яндекс стал учитывать nofollow и вебмастера начали очень редко использовать noidex.
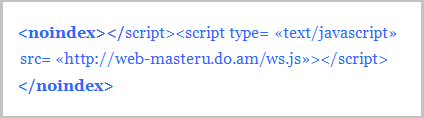
Например, различные коды с использование скриптов. Это связано с тем, что тег noidex в отличие от nofollow закрывает от индексации не определённую ссылку, а конкретный участок кода.
На моём блоге я нигде не использую тег noidex, а применяю только nofollow. Вам тоже, врятли, он понадобится.
Даже баннеры на сегодняшний день очень редко выводятся через скрипт. В основном с помощью php-кода:

Однако, если Вам позарез нужно воспользоваться noidex, прописывать его в коде нужно правильно. Вот несколько рекомендаций:
1. Если в коде используется тег, например вида <div>, то <noindex> ставится перед ним и после закрывающегося тега </div>:

2. В любом скрипте тег ставится в начале <noindex> и в конце скрипта </noindex>:
Проверка закрытия ссылок от индексации
Для того, чтобы проверить, если ли у Вас на сайте не закрытые от индексации внешние или ненужные ссылки, можно использовать специальный сервис для анализа продвижения сайтов: http://be1.ru/stat/.
Переходите по этой ссылке, добавляйте свой блог и Вы сможете просмотреть какие ссылки не закрыты от индекса.
Закрытые ссылки вашего блога на этом сервисе будут помечены красными восклицательными знаками !
Это здорово поможет Вам отыскать незакрытые ссылки и исправить положение. Кроме того, этот сервис помогает увидеть ошибки при использовании тега noindex на своём блоге.
Мне кажется, на сегодня всё. Задавайте вопросы, если что-то не понятно. Применяйте на практике этот метод и продвигайте свой блог.
До новых встреч в новых статьях!
Что такое индексация сайта
Индексация – процесс, результат которого можно сравнить, например, с рентгеновским снимком. Пауки поисковых систем выступают в роли рентген-аппарата, сканируя страницы ресурса и добавляя информацию о них в общую базу данных (или индекс). Краулеры также исполняют роль доктора, в реальной жизни призванного описать снимок. Они не просто фиксируют наличие сайта, но и оценивают контент, юзабилити и другие характеристики, которые напрямую влияют на позиции в рейтинге (или поисковой выдаче). Оценив наполнение и классифицировав ресурс как нечто интересное и полезное, роботы предоставят сайту более выгодные места в выдаче и наоборот.

Получая релевантные ответы на запрос, пользователи даже не задумываются, какой объем работы был проведен роботами поисковых систем для составления перечня ресурсов, на которых представлена требуемая информация. Не догадываются посетители и о трудах, затраченных владельцами сайтов, чтобы интернет-площадки занимали лучшие места в выдаче. Иногда для этого приходится на некоторое время «прятать» ресурс от поисковых ботов для дальнейшей индексации его как полезного и отвечающего всем требованиям посетителей.
У каждой системы разработаны сложнейшие алгоритмы, по которым ведется работа поисковых пауков. Но и «Яндекс», и Google оценивают контент с точки зрения интереса и пользы, приносимой пользователям.
Индексации подвергаются:
текст;
графика (фотографии и картинки);
видео (факт наличия видеоконтента, количество просмотров);
мета-теги (указатели для роботов, позволяющие фиксировать их внимание на важных моментах страницы).
Когда информация о сайте заносится в поисковые базы, ресурс включается в рейтинг, который предстает вниманию пользователя в ответ на соответствующий запрос.

Кажется, совсем недавно достаточно было максимально наполнить текст ключевыми словами, чтобы упростить работу поискового паука и спокойно ожидать появления сайта в ТОПе. Теперь перенасыщение ключами не просто не помогает, а является прямой угрозой попадания под санкции.
Поисковые системы уважают пользователей и заботятся об их удобстве. Разве интересно человеку читать текст, состоящий из ключевых фраз, которые никак не согласуются между собой? Конечно, нет. Более того, не понравится подобный текст и роботам, искусственный интеллект которых развивается в геометрической прогрессии. Они могут «обидеться» всерьез и, признав контент переоптимизированным и бесполезным, отказаться индексировать ресурс вовсе. Наказание может быть и мягким, заключающимся в потере позиций в выдаче, но в любом случае ничего хорошего в некачественном контенте нет. А ведь пауки интересуются еще и навигацией по сайту (удобна ли она пользователям), оценивают юзабилити, ссылочную массу и др.
Наиболее популярен среди владельцев вопрос об ускорении индексации сайта, но иногда возникает необходимость в обратном: лишить роботов возможности оценивать ресурс (полностью или отдельные части).
Выжимка
- robots.txt закрывает сайт от индексирования, но сайт все равно может появиться в результатах поиска.
- Чтобы скрыть страницы или сайт из поиска, используйте метатег robots или X-Robots-Tag HTTP header.
- Метатег robots нужно добавлять на каждую страницу, которую хотите скрыть, по отдельности. Его можно использовать только для html-документов.
- X-Robots-Tag HTTP header позволяет скрыть из результатов поиска сразу весь сайт. Его можно использовать как для скрытия html-документов, так и файлов других форматов – pdf, doc, xml.
- Не нужно запрещать сканирование страницы файлом robots.txt. Если сканирование будет запрещено, краулеры не увидят директивы относительно индексирования и отображения в поиске. Значит, они не выполнят директивы, и сайт появится в выдаче.
Что еще почитать:
Зачем это нужно
Для начала расскажу, почему следует закрывать ссылки, ведущие на другие сайты, от индексации. Если у вас молодой сайт с низкой посещаемостью – эта информация особенно важна.
Итак, основные причины, по которым веб-мастерам необходимо это знать, вот в чем:
- Каждая ссылка, ведущая на чужой сайт и не закрытая через атрибут «nofollow», передаёт вес вашей страницы.
- Используя этот атрибут, опытный веб-мастер может грамотно распределить вес страниц на своём сайте, чтобы выбиться в топ по определенным запросам.
- Возможность закрыть от поисковиков ненужные или низкоприоритетные страницы.
Каждая из причин влияет на продвижение в поисковой выдаче. При грамотном подходе, вполне можно улучшить позиции сайта и суметь выбиться в топ по достаточно конкурентным запросам, даже если ваш ресурс еще молод.
Нормы индексации в Google
Со скоростью индексации в Google ситуация обстоит несколько иначе. На нее может уйти от 1 дня до 2-х недель. Все зависит от показателей вашего ресурса. К примеру, сайты с постоянно обновляющимся контентом (новостники или форумы с высокой активностью) довольно часто посещают роботы. В результате попадание материалов в индекс — вопрос нескольких часов или дней.
Индексация среднестатистических сайтов с еженедельным обновлением контента осуществляется примерно за 2-4 дня. Новые сайты, которые только создали, могут в течение нескольких недель не попадать в индекс.
Если робот получает регулярные сигналы про обновление контента, он будет чаще заходить на такие сайты. Так, вы сможете увеличить скорость индексации новых материалов и получить дополнительный трафик.
Малополезные страницы для пользователей плохо индексируются и часто выпадают из индекса.
Как узнать сколько страниц в дополнительном индексе?
Тут все относительно просто. Покажу на примере моего блога. Запрос в гугле
Покажет сколько страниц в основном индексе, сейчас их «About 558 results».
Запрос без знаков «/&», покажет сколько страниц всего в индексе:
Сейчас у меня в индексе всего «About 1,660 results». Выходит у меня 1660-558=1102 страниц в дополнительном индексе. В основном индексе у меня 34% страниц. Честно говоря, это не такой уж и плохой результат. Если же у вас более 50% страниц в основном индексе, то это уже считается хорошим достижением.
Следующий вопрос конечно будет «А как мне посмотреть какие именно страницы в дополнительном индексе?». Тут уже не все так просто, раньше это можно было выяснить с помощью такого запроса:
То есть показать все страницы в индексе, за исключением страниц из основного индекса. Но сейчас такой запрос не работает.
Я догадался выйти из ситуации другим методом. Разобьем сайт на части и проверим в какой из этих частей больше всего страниц в сопливом индексе. Например если вы увлекаетесь тегами, то таких страниц в сопливом индексе должно быть достаточно много, так как там дублирующийся контент, а если еще страница с тегом указывает только на одну-две статьи, то этого контента раз-два и обчелся. Под страницей с тегами подразумеваю страницы с такими адресами: elims.org.ua/blog/tag/span/
Итак, запрос «site:elims.org.ua inurl:/blog/tag/» показал 254 результата, а запрос «site:elims.org.ua/& inurl:/blog/tag/» — 3 результата. Выходит 251 страница с тегами основного подблога «/blog/» находится в сопливом индексе. Теперь я знаю над чем можно поработать. По аналогии можно проинспектировать остальные части сайта.
Как запретить роботам доступ к ссылкам на определённом порту
Предположим, есть частный веб-сервер, настроенный на нетрадиционный порт (скажем, 6677). Все люди могут иметь доступ ко всем URL-адресам сайта на порту 6677. Ссылки с mysite.ru:6677 также проиндексированы Google, что может быть нежелательно.
Итак, как я могу запретить доступ к страницам сайта в robots.txt на нестандартном порте?
Если вы хотите запретить сканеру доступ к example.com:6677 с помощью robots.txt, вам просто нужно разместить файл robots.txt на соответствующем порту, то есть: http://example.com:6677/robots.txt
Спецификация не позволяет указывать порт в самом файле robots.txt. Все указанные пути используют тот же протокол, номер порта и хост, с которого осуществляется доступ к файлу.
Но, как уже говорилось в этой статье, запрет в robots.txt необязательно предотвращает индексирование URL-адреса; он предотвращает попадание в индекс поисковых систем.
То есть, предыдущий совет подойдёт для тех, у кого сайт на нестандартном порту является отдельным виртуальным хостом со своим собственным содержимым.
Но если один и тот же сайт доступен как с порта 80, так и с порта 6677, но только порт 6677 должен быть заблокирован для поисковых роботов, то предыдущий способ не подойдёт. Поскольку оба порта обращаются к одному и тому же сайту, они оба будут использовать общий файл robots.txt, и поэтому оба сайта будут заблокированы, если только разные файлы robots.txt не показываются зависимости от того, какой порт использовался для доступа к сайту.
В такой ситуации необходимо проверить порт в серверном скрипте и отправить клиенту соответствующий тег META или заголовок HTTP-ответа. В PHP вы можете сделать это примерно так:
<?php
// Блокируем роботов от доступа к порту 6677
if ($_SERVER == '6677') {
header('X-Robots-Tag: noindex');
}
?>
Помните, что все заголовки должны выводиться строго до отправки других данных, поскольку после отправки данных заголовки уже отправлены и изменить их позже невозможно — это вызовет ошибку в PHP.
Можно пойти кардинально и запретить доступ поисковым систем к определённому порту, добавив примерно следующие правила в файле .htaccess:
# Блокируем доступ Google к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Google
RewriteRule .* -
# Блокируем доступ Yandex к порту 6677:
RewriteCond "%{SERVER_PORT}" "^6677$"
RewriteCond %{HTTP_USER_AGENT} Yandex
RewriteRule .* -
Связанные статьи:
- Как защититься от спама через формы обратной связи (80.9%)
- Как в mod_rewrite блокировать по Referer, User Agent, URL, строке запроса, IP и в их комбинациях (59.2%)
- Какую информацию собирает Google — как просмотреть и удалить (54%)
- А как долго на ваших сайтах «залипают» пользователи? (50.4%)
- Как сбросить пароль WordPress без доступа к почте (50.4%)
- Не работает перенаправление на HTTPS в WordPress (RANDOM — 50.4%)
Как проверить закрыта ли страница от индексации
Итак, вы воспользовались одним из методов
скрытия внешних ссылок или скрыли контент от поисковых ботов. Как теперь
убедиться, что операция произведена правильно, а файл robots.txt в корневой папке файла выполняет свою прямую
функцию? Разберем последовательность действий на примере браузера Яндекс:
- откроем главную страницу сервиса Яндекс Вебмастер;
- найдем раздел «Инструменты». Для тех, кто не знаком с этой опцией, искать необходимо в правом верхнем углу на панели инструментов;
- в открывшемся функциональном окне выбираем графу «Проверка ответа сервера»;
- в поле «Опрашиваемый URL» вводим URL адрес той страницы, которую вы скрыли от индексации;
- нажимаем на кнопку «Проверить» и ждем ответа;
- положительный результат – это ответ сервиса в виде записи «Данный URL запрещен к индексированию в файле robots.txt».
Все, проверка прошла успешно и показала, что
все ваши действия были правильными.
Настройка через хостинг и плагин
Если вы создаете файл самостоятельно, то для работы с ним рекомендуется использовать текстовый редактор, который не добавляет лишний код в разметку, например, Notepad++.
Основные директивы, которые понадобятся в настройке robots.txt через хостинг или плагин, например, Yoast SEO — выглядят следующим образом:
- User-agent: — указывает к каким поисковым роботам применяется правило, например, Yandex, * (роботы всех ПС), Googlebot;
- Disallow: — запрещает индексацию;
- Allow: — индексация разрешена;
- Sitemap: — указывает на расположение файла sitemap.xml. В данном файле содержатся все страницы, предназначенные для индексирования;
- Host: — указывает на главное зеркало сайта, например, https://домен.ru/. В данный момент, директива Host не используется и прописывать ее в файле robots.txt — не надо.
Как запретить индексирование сайта в robots.txt
Чтобы запретить индексирование сайта в robots.txt для всех поисковых роботов, используйте следующую конструкцию:
User-agent: * Disallow: /
robots для блога/сайта на WordPress
Файл robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Для WooCommerce
Файл robots.txt для WooCommerce выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /tag Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Готовый файл robots.txt загрузите на хостинг, в корень сайта или создайте его там через стандартный менеджер файлов и сохраните изменения.
Повторюсь, если редактируете robots.txt на компьютере или работаете с любым другим файлом, который содержит в себе код, то используйте для этого Notepad++.
Для примера, этот текст написан в OpenOffice и если его скопировать и вставить, например, в онлайн HTML-редактор, то увидите это:
Некоторые редакторы автоматически добавляют теги разметки в текст, а чтобы этого не происходило — используйте предназначенные для этого инструменты.
Настройка через плагин Yoast SEO
Если у вас установлен плагин Yoast SEO, то для создания и редактирования файла robots.txt в нем предусмотрена эта функция.
Для того,чтобы создать или редактировать — перейдите в настройки «SEO» и выберите пункт «Инструменты».
Если файла нет, то плагин предложит создать его.
Для этого нажмите на соответствующую кнопку «Создать файл robots.txt». В поле ниже автоматически появятся следующие строки:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Если вы хотите запретить поисковым роботам индексировать сайт на момент разработки, то измените содержимое на:
User-agent: * Disallow: /
Если вы готовы запустить проект, то настройте содержимое файла через редактор плагина.
Не забудьте сохранить настройки.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Инструмент проверки индексации от PromoPult
Для быстрой проверки индексации онлайн в Яндексе и Google в PromoPult разработали инструмент для анализа индексации страниц.
Что он умеет:
- одновременно проверять проиндексированные страницы в Яндексе и Google (или только одной из тих ПС);
- проверять сразу все URL сайта из XML-карты;
Особенности инструмента:
- работа «в облаке»;
- выгрузка отчетов в формате XLSX;
- уведомление на почту об окончании сбора данных;
- хранение отчетов неограниченное время на сервере PromoPult;
- нет ограничений по количеству URL.
Как проверить индексацию страниц с помощью инструмента PromoPult
Шаг 1. Добавьте URL на проверку
Перейдите на страницу инструмента и добавьте URL, которые нужно проверить. Делается это одним из трех способов:
Добавление XML-карты сайта (вариант подходит, если вам нужно проверить все URL сайта; для этого укажите полный путь к карте сайта в формате http://www.site.ru/sitemap.xml).

Загрузка XLSX-файла (в этом случае система проверит все URL, указанные на первом листе сайта; расположение URL по столбцам и строкам не имеет значения).

Добавление списка URL вручную (вариант подходит, если вам нужно проверить не все URL сайта, а только некоторые из них; каждый URL прописывайте с новой строки).

В зависимости от того, из какого источника вы будете брать URL, решаются разные задачи.
Из XML-карты сайта или CMS
В этом случае можно проверить, какие из важных URL не проиндексированы.
Пример. В карте сайта 1250 URL, которые подлежат индексации. Мы вводим поочередно в Яндексе и Google команду:
site:yourdomain.ru
Получаем количество проиндексированных страниц – 684 и 1090.
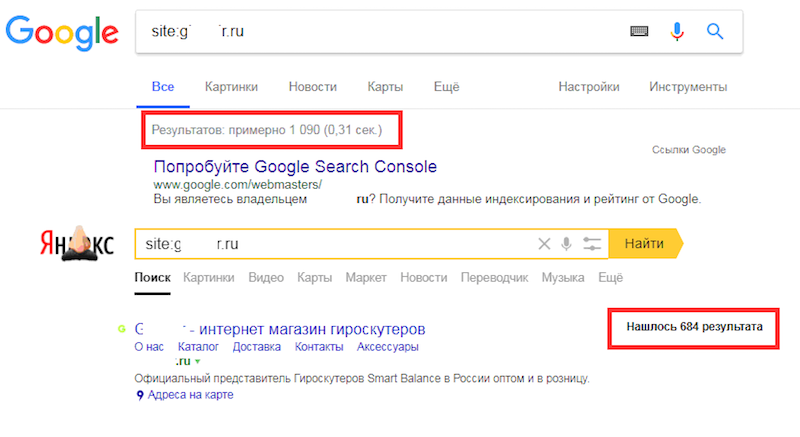
Задача – определить, каких страниц не хватает. Сканируем XML-карту сайта с помощью инструмента от PromoPult, получаем информацию по всем URL и выявляем несоответствия.
Из отчета о проиндексированных страницах из Яндекс.Вебмастера или Google Search Consol
Бывает, что в каком-то поисковике количество проиндексированных страниц превышает количество URL в карте сайта. В такой ситуации необходимо загрузить на проверку все URL из поисковика, в котором наблюдается такое превышение, – это позволит выявить «лишние» страницы.
Пример. В карте сайта 15 570 URL, которые подлежат индексации. Проверяем количество страниц по команде site:yourdomain.ru в Яндексе и Google:
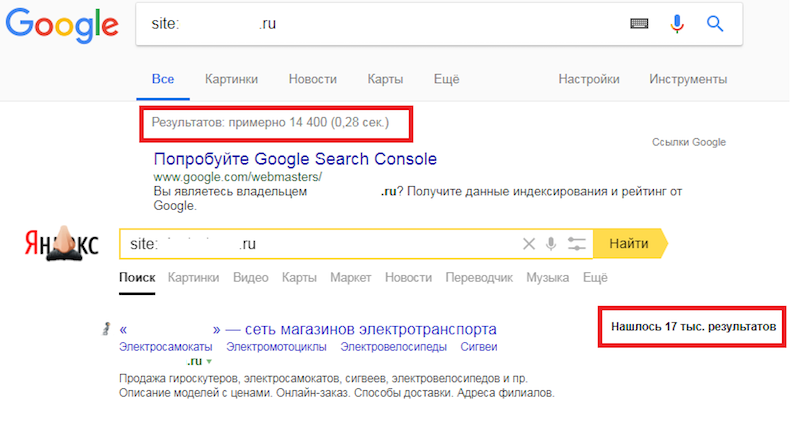
В Яндексе количество страниц превышает количество страниц не только в Google, но и в карте сайта. Очевидно, что в индекс попали нежелательные страницы. Если запустить проверку только по URL из карты, мы так и не узнаем, какие URL «лишние». Поэтому переходим в Яндекс.Вебмастер, выгружаем все страницы из поиска и проверяем их. Теперь проще разобраться, в чем проблема.
На данном этапе выберите ПС для проверки индексации. Для выявления расхождений выберите две системы.

Шаг 3. Загрузка отчета
После проверки отчет появится в «Списке задач». Кроме того, вам на почту придет уведомление:

Загрузите отчет в формате XLSX:

В файле два листа: результаты анализа и исходные данные. На первом листе 3 столбца: URL и данные по индексации (1 – страница проиндексирована, 0 – нет).
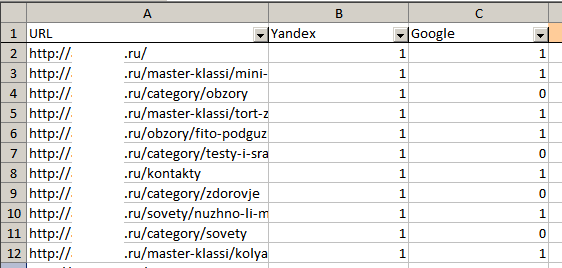
С помощью автофильтра вы легко определите, каких страниц не хватает в Яндексе или Google:
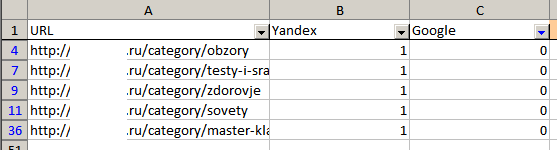
Пять вариантов закрыть дубли на сайте от индексации Яндекс и Google
1 Вариант — и самый правильный, чтобы их не было — нужно физически от них избавиться т.е при любой ситуации кроме оригинальной страницы — должна показываться 404 ответ сервера
2 Вариант — использовать Атрибут rel=»canonical» — он и является самым верным. Так как помимо того, что не позволяет индексироваться дублям, так еще и передает вес с дублей на оригиналы
Ну странице дубля к коде необходимо указать
<link rel="canonical" href="http://www.examplesite.ru/url originalnoi stranicu"/>

3 Вариант избавиться от индексации дублей — это все дублирующие страницы склеить с оригиналами 301 редиректом через файл .htaccess
4 Вариант — метатеги на каждой странице дублей
5 Вариант — все тот же robots
Может пригодиться: продвижение сайта по трафику в Москве — готовы ли вы к приливу посетителей?
Как закрыть сайт от индексации в WordPress?
Данный способ, наверное, самый простой, и владельцам сайтов, которые созданы на базе CMS WordPress, очень повезло. Дело в том, что в данной CMS предусмотрена возможность закрытия сайта от индексации при установке движка на хостинг. В случае если вы не сделали этого при установке, вы всегда можете это сделать в настройках. Для этого вам нужно:
- 1.В админпанели переходим в раздел «Настройки» → «Чтение».
-
2.Перелистываем открывшуюся страницу в самый низ, и отмечаем галочкой опцию показанную на скриншоте:
- 3.Сохраняем изменения.
Все. Теперь ваш сайт не будет индексироваться. Если открыть страницу в браузере и нажать комбинацию клавиш CTRL+U, мы сможем просмотреть код страницы, и увидим вот такую строку кода:

Данная запись была добавлена автоматически, после того как мы включили опцию запрета индексации в настройках.
Главное не забыть отключить эту опцию после завершения работ:)