3 лучших расширения яндекс wordstat
Содержание:
Ответы на вопросы, хитрости при работе с «Вордстатом»
За годы работы с «Вордстатом» у меня накопилась небольшая методичка по ответам на часто задаваемые неочевидные вопросы. Думаю, вы найдете что-то полезное.
Собрали кучу данных
Как проводить анализ запросов? На что обращать внимание?. В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее
Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
В первую очередь обращаем внимание на коммерческие запросы, у которых частота без кавычек и в кавычках отличается плюс-минус в 2 раза или менее. Если при еще и слабая выдача (нет нормальных предложений), вообще отлично
Чем больше расхождение в цифрах, тем больше у вас шанс не угадать намерение пользователя. Например, запрос «боковое стекло хендай» плохой, потому вообще непонятно, что ищут. Дефлектор бокового стекла? Само стекло? Левое? Правое? Переднее? Купить или продать?
Пример хорошего запроса:
2. Как посмотреть статистику запросов для одного города?
Выберите свой город в настройках региона. Помимо города хорошо бы понимать целевую аудиторию и дополнительно затачивать сайт под целевую аудиторию. Например, эвакуатор или вскрытие дверей почти наверняка будут искать со смартфона или планшета.
3. Как обойти ограничение на длину запроса в 8 слов?
Через «Вордстат» такие данные собрать нельзя. Запросы из 8 и более слов можно собрать в поисковых подсказках, найти в различных базах запросов или получить в статистике своего сайта.
4. Что означают абсолютные и относительные данные в истории запросов?
Абсолютный показатель – это фактическое цифровое значение, сколько было таких запросов за период. Относительное значение показывает популярность запроса среди всех запросов в поиске.
5. Что делать, если «Вордстат» собрал 2000 запросов, но нужно больше?
В широких нишах на 40-й странице «Вордстата» только начинается самое интересное:
Если в «Вордстат» ввести запрос в кавычках, повторяя основное слово, вы увидите все запросы из Х слов, содержащих нужное слово. Х – количество слов во фразе в кавычках. Пример:
Используя поочередно конструкции:
- «налог налог налог налог налог налог налог»
- «налог налог налог налог налог налог»
- «налог налог налог налог налог»
- «налог налог налог налог»
- «налог налог налог»
- «налог налог»
- налог
Можно собрать все запросы, которые содержат слово «налог» или его склонения.
6. Как провести массовую проверку частотности запросов из «Вордстат»?
Массово проверить все частотности фраз можно сделать в «Кей Коллекторе» или его бесплатном аналоге – программе «Словоеб».
7. Как убрать капчу в «Вордстате»?
Причина появления капчи – большое количество запросов с 1 IP адреса. Вы можете или сменить айпишник, или использовать программы для работы с «Вордстатом» вместе с сервисами разгадывания капчи.
8. Почему у «Вордстата» ограничение длины в 7 слов?
«Вордстат» изначально был создан как сервис статистики для «Яндекс Директа», в котором максимальное количество слов в рекламной фразе – 7. Никаких других причин для ограничения запроса нет.
Источник статьи
Упрощение работы со статистикой Яндекс Wordstat
Если нужно собрать сразу большой объем ключевых слов, Вордстат становится не слишком удобной программой. Но есть программы, которые помогают ускорить процесс:
Yandex Wordstat Assistant
Удобное приложение для вашего браузера, которое позволяет создавать списки, содержащие ключевые слова из Яндекс Вордстат. После окончания работы их можно отсортировать или скопировать с базовой частотностью или без.

Плюсы Yandex Wordstat Assistant:
- Бесплатно.
- Простое расширение в браузере, а не ПО.
Минусы Yandex Wordstat Assistant:
Данные только с базовой частотностью.
Yandex Wordstat Helper
Похожее на Yandex Wordstat Assistant расширение для браузера, но с немного более удобной сортировкой.

Плюсы Yandex Wordstat Helper:
- Бесплатно.
- Просто.
Минусы Yandex Wordstat Helper:
- Долго.
- Не подходит для быстрой обработки большого пула данных.
Key Collector
Это наиболее удобная программа для получения статистики ключевых запросов из Яндекс Вордстат. Кроме того, она собирает запросы также из Google Ads.

- Быстрый автоматизированный сбор ключевых слов.
- Удобна при работе с большими объемами данных.
- Поиск из данных Яндекса и Гугл.
Минусы Key Collector:
- Платная.
- Нужна первоначальная настройка, которая может вызвать небольшие затруднения.
- Нужно будет оплатить антикапчу, чтобы не тратить время на введение вручную.
Дополнительные операторы
В Yandex WordStat есть еще 5 дополнительных операторов, которые открывают еще больше возможностей по поиску ключевых слов.
1. Квадратные скобки []
Если напишем внутри скобок при запросе конкретное словосочетание, то оно останется в таком порядке, как мы его прописали.
2. Оператор плюс +
Помогает отыскать поисковые запросы, где есть символы, например, предлоги и так далее.
3. Оператор «или»
Используется символом | и применяется для оперативного подбора семантики на веб-страницу, а также для сравнения или смещения некоторых фраз.
4. Оператор группировка ().
Внутри этого оператора прописываются вышеперечисленные символы, чтобы использовать их вместе.
5. Оператор минус.
Обозначается символом — он убирает запросы, которые содержат ненужные слова при изучении статистики слова.
Примеры операторов
1. Квадратные скобки, они фиксируют порядок слов.
2. Оператор +
При этом запросе отражаются все слова купить с прелогом «в» Зтот оператор зафиксировал все слова с предлогом в»
Оператор мнус —
3. Группировка
Мы рассматривали только все плюсы операторов Вордстат, а теперь давайте посмотрим есть ли у них недостатки.
Работа с операторами Вордстата
Можно искать данные, просто вбивая запрос в поиск по сервису, но для конкретизации запросов есть операторы — добавочные символы с уточнениями. Они работают на вкладках поиска по словам и по регионам, на вкладке с историей запросов можно использовать только оператор «+запрос».
Обязательные слова
+запрос — оператор делает обязательным слово, перед которым стоит. Обычно его применяют для важных предлогов. Сервис учитывает разные формы слова, иногда из-за этого меняется смысл, а правило для предлога позволяет отсечь лишнее.
 Оператор «+» в Вордстате
Оператор «+» в Вордстате
Минус-слова
-запрос — позволяет вычеркнуть из результатов запросы со словами, которые не должны в них встречаться. Обычно минусуют слова, размывающие тему, в коммерции убирают запросы с самостоятельным решением проблемы.
 Оператор «-» в Вордстате
Оператор «-» в Вордстате
Точная словоформа
!запрос — оператор фиксирует окончание у слова, перед которым находится. Сервис покажет только запросы, где слово употреблено в заданной вами форме — нужном числе и падеже, с таким же окончанием.
Без дополнений
«»запрос»» — запрос в кавычках значит, что сервис покажет запросы без дополнений — хвостов, четко с указанным количеством слов.
При этом если какое-то слово или предлог в запросе дублируется, сервис добавит в результаты запросы, где на месте дубля другое слово. Запрос с двумя предлогами «в»:
 Оператор «!» в Вордстате
Оператор «!» в Вордстате
Комбинируя операторы с кавычками и восклицательным знаком, можно достать более точные значения по нужной фразе без лишних сочетаний.
К примеру, по запросу «купить компьютер» выходят и запросы про очки, блок питания и другие сопутствующие предметы с частью «для компьютера», а с уточняющим словоформу оператором запросы сужаются.
 Операторы «!» и «» в Вордстате
Операторы «!» и «» в Вордстате
Длинные ключи в Wordstat
С помощью оператора с кавычками и повторения ключа можно достать больше интересных запросов из глубины Wordstat. Вбейте в поиск конструкцию «запрос запрос запрос запрос запрос запрос», то есть одинаковый запрос Х раз в кавычках, тогда сервис выведет запросы длиной в Х слов с употреблением этого ключа.
 Способ найти более длинные ключи с помощью оператора «»
Способ найти более длинные ключи с помощью оператора «»
Обычный парсинг не даст собрать такие запросы. Количеством употреблений нужного слова можно регулировать длину запросов.
Точный порядок слов
— оператор с квадратными скобками делает строгим порядок слов в запросе
Часто это важно при географических запросах в логистике и туризме
 Оператор «» в Вордстате
Оператор «» в Вордстате
Группировка операторов
(запрос запрос) — этот оператор делает возможным группировку нескольких операторов. Тогда сервис учитывает их одновременно для указанных в скобках слов.
 Группировка операторов в Вордстате
Группировка операторов в Вордстате
Синонимы
(запрос|запрос) — оператор позволяет указать синонимы для вариативности. Работает вместе со скобками для группировки. С такими операторами сервис будет искать запросы, выбирая слова из предложенных синонимов.
 Оператор «|» в Вордстате
Оператор «|» в Вордстате
Инструменты для упрощения работы с «Вордстатом» – расширения и программы
Работать с «Вордстатом» просто – научиться сносно пользоваться пятью операторами можно за полчаса. А вот собирать большие объемы данных и работать с ними – уже сложнее. В первой части статьи были рассмотрены основы работы с «Вордстатом», потому что без понимания какие данные и почему отдаются сервисом, невозможно эффективно использовать средства автоматизации. Вот три самых популярных программы:
- «Яндекс Вордстат Ассистент»;
- «Яндекс Вордстат Хелпер»;
- «Кей Коллектор» (и его бесплатная версия).
«Яндекс Вордстат Ассистент»
На официальном сайте https://semantica.in/tools/yandex-wordstat-assistant выбираем браузер, который используется для работы. После установки возле каждого запроса появится возможность добавить или удалить его из списка:
Все «проплюсованные» запросы добавляются в список. После того, как все нужные запросы скопированы в список, можно:
- Посмотреть в списке количество добавленных фраз и их суммарную частотность (цифры 2 и 25 над списком на скриншоте выше).
- Скопировать фразы в буфер обмена.
- Скопировать фразы и их частотность в буфер обмена.
- Отсортировать запросы по убыванию или по возрастанию в алфавитном порядке, по порядку добавления в список или по частотности.
Основной плюс – простота использования, дополнение бесплатное. Основной минус – инструмент собирает только фразу и базовую частотность запроса.
«Яндекс Вордстат Хелпер»
Установить дополнение можно также выбрав браузер на странице официального сайта https://arcticlab.ru/yandex-wordstat-helper/
Фактически, это полный аналог предыдущего дополнения, но чуть более удобный (сортировку можно сделать в 1 клик).
Еще один недостаток обоих дополнений – муторная ручная работа при работе с большим количеством запросов. Я уже писал ранее, что популярный запрос может отдавать данные на 40 страницах по убыванию частотности. Чтобы только собрать эти данные, нужно будет произвести более 80 кликов (40 переходов на следующую страницу и 40 добавлений запросов в дополнение).
«Кей Коллектор», описание и настройка парсера данных из «Яндекс.Вордстат»
По сути, это комбайн для работы с данными. Я не буду пересказывать справку программы, а напишу только о плюсах и минусах «Кей Коллектора» при работе с «Вордстатом».
Сначала о минусах. Их всего четыре:
- Как я уже писал, программа платная.
- Потребуется завести отдельные аккаунты в «Яндексе» для «Кей Коллектора», так как при частых автоматических запросах может быть затруднен доступ к «Вордстату» (будет выбиваться несколько капч на каждый запрос).
- Нужно будет 1 раз настроить программу по справке или по скриншотам моих настроек для быстрого сбора данных.
- Потребуется оплатить 1 из сервисов антикапчи, чтобы можно было поставить программу на сбор данных и забыть о ней. Хотя я собираю данные в промышленных объемах (сотни тысяч запросов в месяц), мне на 3 компьютера хватает 150–350 рублей в месяц на оплату антикапча-сервисов.
Теперь интерфейс:
Полный обзор возможностей программы лежит за рамками темы о «Вордстате», потому что краткий видео обзор возможностей программы занимает около полутора часов. Я обозначу только настройки, которые нужны для того, чтобы быстро начать работать с «Вордстатом».
Три волшебных кнопки:
- Сбор фраз из «Яндекс Вордстат». Аналогично тому, как если бы вы руками с каждой страницы копировали запрос и частотность в таблицу.
- Сбор поисковых подсказок. Если вы каждую фразу будете вставлять в поиск и выписывать для нее поисковые подсказки – получите такой же результат, как и программа.
- Сбор частотностей в кавычках «» и с уточнением словоформы «!». Работает так же, как если бы вы каждый запрос вбивали с этими операторами и записывали цифры.
Порядок действий – сначала собираем запросы (1), затем частотность (3). По интересующим запросам собираем подсказки (2) и снова частотность (3).
Полученный результат:
Фактически, сбор десятков тысяч запросов со всеми данными занимает 2-3 часа.
Я приведу настройки, которые нужно сделать, чтобы собирать данные с лучшим сочетанием скорости и дешевизны (не супер быстро, но с небольшим расходом на антикапчу). По порядку:
Сбор разных видов частотностей проходит через «Яндекс.Директ» – настраиваем и его:
Кроме этого в верхней части этого окна нужно добавить несколько аккаунтов «Яндекса»:
И последнее что нужно сделать – зарегистрироваться в любом из совместимых сервисов разгадки капчи, получить в нем код для работы и ввести его в настройках:
Я пробовал разные схемы настроек, эта – самая эффективная и простая.
Остальные 200 кнопок и настроек я предлагаю вам освоить самостоятельно (-:
Существует и бесплатная версия «Кей Коллектора» – программа «Словоеб», которая так же позволяет полноценно работать с «Вордстатом». Ссылка на сайт программы.
Описание
Wordstat Yandex или Подбор слов — это бесплатный сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Яндекс Вордстат можно оценить сезонность и географическую зависимость поисковых запросов.
Особенности работы сервиса
- Wordstat не работает без регистрации. Ранее такая возможность была, однако с недавних пор инструмент запускается только после авторизации в Яндекс. Почте.
- Вордстат фильтрует пользователей. Под фильтры системы можно попасть из-за нарушения лицензии на использование Яндекса, а также из-за DDOS-атак на сервис с вашего компьютера в результате деятельности вируса. Стоит отметить, что в качестве атаки на сервер может быть воспринята работа специальных парсеров – программ, собирающих ключевые словосочетания в автоматическом режиме (например, Key Collector).
- Периодически при работе может выскакивать Captcha, приостанавливающая работу с Вордстатом. Возникает это из-за некорректного IP-адреса (для пользователей из не постсоветских стран), закрытых файлов cookie или отсутствии поддержки JS-скриптов на компьютере.
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
Операторы Вордстат
- Оператор «-» (минус-слово). Позволяет исключить слово из статистики запросов. Применяется отдельно для каждого слова. Чтобы исключить словосочетание, необходимо добавлять оператор минус перед каждым словом в поисковой строке сервиса.
- Оператор «+» (учет стоп-слов). Позволяет учитывать в статистике союзы и предлоги во всех словоформах, которые игнорируются поисковой системой. При детализации запроса (левая колонка) оператор «+» по умолчанию используется во всех фразах, содержащих стоп-слова.
- Оператор «|» (логическое «или»). Позволяет получить статистику одновременно по нескольким условиям. Работает по правилу логического «или».
- Оператор «()» (логическое «и»). Необходим для группировки запросов, а в паре с оператором «|» позволяет создать регулярное выражение и получить список поисковых фраз по комбинации условий.
- Оператор «» (словоформа). В данном случае фиксируется запрос, поэтому из статистики удаляются дополнительные слова. Учитываются различные окончания, стоп-слова, но не учитывается порядок слов.
- Оператор «!» (точное вхождение). Его использование запускает фиксацию словоформы, т.е. будет учтена фраза только с текущим окончанием слов, но не учитывается порядок слов в запросе.
- Оператор «[]» (учет порядка слов). Необходим чтобы зафиксировать порядок слов в запросе. При этом будут учитываться словоформы и стоп-слова.
Что такое Яндекс Wordstat
Яндекс Wordstat — бесплатный сервис, предназначенный для сбора статистики поисковых запросов в Яндексе. Он помогает рекламодателям и веб-мастерам понять популярность тех или иных ключей, выявить тренды, а также спрос на товары и услуги.
На деле Wordstat отображает прогнозное количество показов ключа в месяц на основе существующей статистики поиска, не включая РСЯ. В списках приводятся как различные вариации исследуемой фразы, так и те, которые наиболее часто ей сопутствуют. На этой основе можно делать выводы о смежных сферах интересов пользователей, которые затем использовать в кампании.
Благодаря сервису у специалиста появляется возможность:
- Собрать основу семантического ядра;
- Ранжировать популярность запросов по регионам;
- По устройствам;
- Выявить сезонность.
А с Calltouch можно анализировать результаты проделанной работы.
Сквозная аналитика
от 990 рублей в месяц
- Автоматически собирайте данные с рекламных площадок, сервисов и CRM в удобные отчеты
- Анализируйте воронку продаж от показов до ROI
- Настройте интеграции c CRM и другими сервисами: более 50 готовых решений
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Кастомизируйте таблицы, добавляйте свои метрики. Стройте отчеты моментально за любые периоды
Узнать подробнее
Между тем, существует ряд ограничений на работу с сервисом. Так, для качественного парсинга и анализа всех ключевых слов специалисту придётся использовать дополнительное программное обеспечение или плагины. Дело в том, что поиск по статистике Яндекса возможен только в ручном режиме. Процесс отсеивания и сбора ключевых фраз становится рутинным и трудоёмким в связи с невозможностью их загрузки на компьютер стандартными средствами сервиса. Из-за этого сбор семантического ядра через Wordstat не может быть произведён в полном объёме, если не прибегать к сторонним инструментам.
Вместе с этим, составление ядра затрудняется и ограничением по объёму выдачи. Если ваш запрос имеет много вариаций и весьма популярен в различных формах, вы вероятно не сможете проанализировать и использовать их все. Вордстат позволяет просмотреть лишь 2000 строк результата — 40 страниц по 50 фраз. Если за пределами остаются важные низкочастотные ключи, вы с трудом сможете их достать стандартными средствами.
Более того, для пользования Wordstat вы должны войти в Яндекс аккаунт. Уже в процессе работы с сервисом вы рискуете постоянно вводить капчу и даже быть забаненными в случае злоупотребления поиском однотипных запросов. Чтобы продолжать пользоваться сервисом в нормальном режиме, вы можете попробовать вводить слова в разных падежах. Например: вордстат Яндекс, вордстата Яндекса.
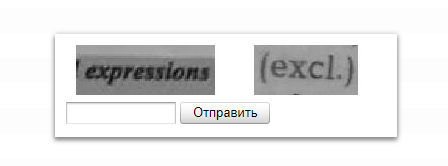
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Особенности учета словоформ Вордстата
Объединение словоформ. Фразы считаются словоформами, если это:
- Склонения числительных падежам (три, трех, трем, тремя);
- Склонения существительных по падежам и числам (слон, слоны, слонами, слонов);
- Изменения суффиксов у глаголов (бежать, бежит);
- Причастия, деепричастия, глаголы и их спряжения (просмотреть, просмотрел, просмотревший, просмотренный);
- При изменении «ё» на «е» и наоборот (елка,ёлка);
- Числа, падежи, форма и степень прилагательных (высокий, выше, высочайший).
В некоторых случаях количество запросов может отличаться из-за учета фраз, характерных только для одной из них:
Например, слово «тертый» появляется при поиске по запросу «три», но не показывается по запросу «трех». Не стоит забывать, что эта особенность характерна только для общей (базовой) частотности. Чтобы получить точное значение необходимо использовать оператор «точное вхождение» (восклицательный знак).
Разделение словоформ. Фразы не считаются словоформами, если это:
- Ошибки в словах (витамины, ветамины);
- Синонимы (чашка, кружка, стакан);
- Сленг или жаргон (препод, преподаватель);
- Транслитерация (яндекс, yandex);
- Сложносоставные слова (электроинструмент, электро инструмент);
- Глаголы, образованные за счет приставок (ехать, приехать, заехать);
- Уменьшительно-ласкательные формы (машина, машинка);
- Существительные, имеющие разный род (собака, пес);
- Числительные с одним значение, но разным написанием (10, десять, десятый);
Как работать с Вордстатом
Сервис подбора слов помогает просматривать обобщенную статистику по запросам, а также оценивать частотность в зависимости от различных факторов. В Wordstat также есть набор операторов, с помощью которых можно узнать реальное число запросов для определенной формы слова или фразы.
Фильтры
Чтобы посмотреть статистику в срезе по устройствам, используйте фильтр. Он доступен в каждом разделе. Wordstat разделяет мобильные устройства на телефоны и планшеты.
Для просмотра данных по разным регионам, нажмите «Все регионы». Откроется окно, где можно уточнить регион показов.
Переключитесь на вкладку «По регионам», чтобы узнать число показов страниц по запросам из конкретного города, страны или региона, а также по все регионам вместе. Здесь можно посмотреть статистику на карте, если удобно. Также можно применить фильтры по устройствам, чтобы сузить поиск.
Здесь доступны два столбца с цифрами:
- «показов в месяц» — количество показов из региона за месяц;
- «региональная популярность» — доля, которую занимает регион в показах по данному слову, деленная на долю всех показов результатов поиска в этом регионе.
100% — это среднее значение. Если оно меньше 100%, то интерес пользователей к этому слову понижен, и наоборот.
Яндекс уточняет, что региональная популярность — это affinity index в отчетах Яндекс.Метрики.
Следующий раздел в интерфейсе — «История запросов». В первую очередь он помогает подобрать слова для бизнесов, где ярко выражена сезонность и не получается собрать семантику на основе статистики за месяц. В «Истории запросов» показывается динамика показов за два года.
Статистику можно смотреть в абсолютных или относительных значениях. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.
Операторы
Операторы в Wordstat помогают уточнить запросы и получить более детальную статистику по ним. Их можно применить только во вкладках «По словам» и «По регионам». Рассмотрим основные операторы, которые пригодятся специалисту на начальном этапе работе.
-
Кавычки фиксируют количество слов в запросе. Это помогает посмотреть, сколько раз пользователи вводили эту фразу. Система учитывает разный порядок слов и разные окончания. Повторяющиеся слова считаются за одно слово.
- Восклицательный знак нужен, чтобы посмотреть статистику по конкретной форме слова. Он ставится перед словом, которое не должно видоизменяться.
- С помощью оператора «Плюс» можно включать в запрос предлоги или другие служебные слова.
- «Минус» исключает слова из запроса.
- Если заключить ключевую фразу в квадратные скобки, система выдаст число запросов для фразы с сохранением порядка слов. При этом учитываются разные словоформы и предлоги.
Посмотрим на примеры использования. Если нужно узнать точное количество запросов исключительно по заданной фразе без дополнительных слов и без учета словоформ, нужно использовать два оператора: кавычки и восклицательный знак.
Чтобы исключить запросы, не совпадающие с тематикой продвижения, используйте оператор минус вместе с восклицательным знаком. Как в известном примере, вы не будете показывать рекламу бильярдного кия пользователям, которые интересуются покупкой машины Kia и ошиблись в правописании.