Топ-13 сервисов для сбора ключевых слов и формирования семантического ядра
Содержание:
Ключевые идеи статьи
1. Не ограничивайтесь самыми очевидные ключевыми словами! Подберите релевантные, но нестандартные формулировки, которые принесут вам недорогие клики и конверсии.
2
Уделяйте большое внимание минус-словам. Чем полнее и ваш список минус-слов, тем меньше нецелевых показов и кликов получите
3. Информационные запросы используйте только если есть подходящие посадочные страницы для них. Генерировать прямые продажи по инфо-запросам будет сложно.
4. Пользы от больших семантических ядер нет. Для большинства кампаний несколько десятков или сотен запросов вполне достаточно, чтобы получить релевантный трафик по максимально низкой цене.
Если же у вас возникли трудности с подбором ключевых запросов для Яндекс Директ или Google Рекламы, или другие проблемы при запуске или ведении кампаний, обращайтесь к нашим специалистам.
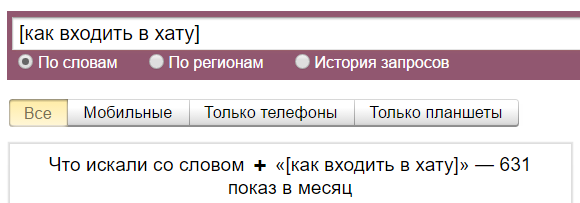
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
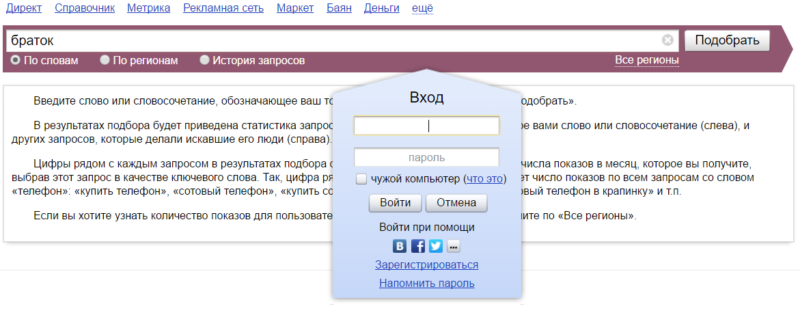
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:
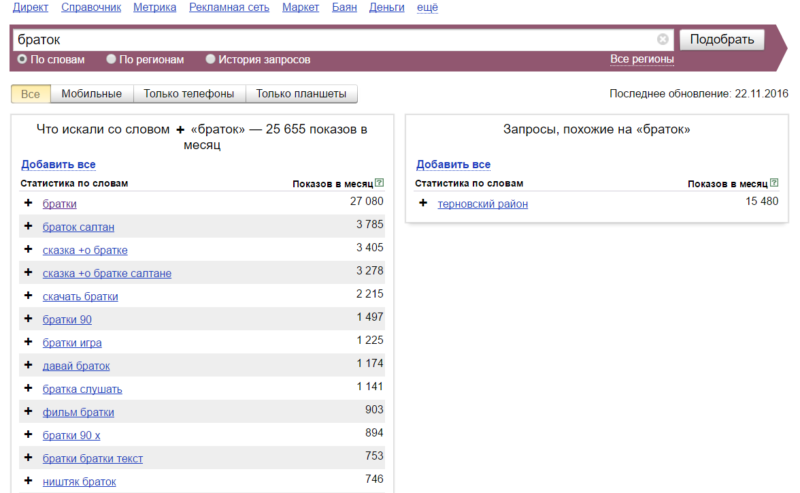
Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
Давайте теперь смотреть остальные функции интерфейса:

В блоке 1 — переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.В блоке 2 — очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.В блоке 3 — дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.В блоке 4 — выбираем регион/регионы.
По регионам
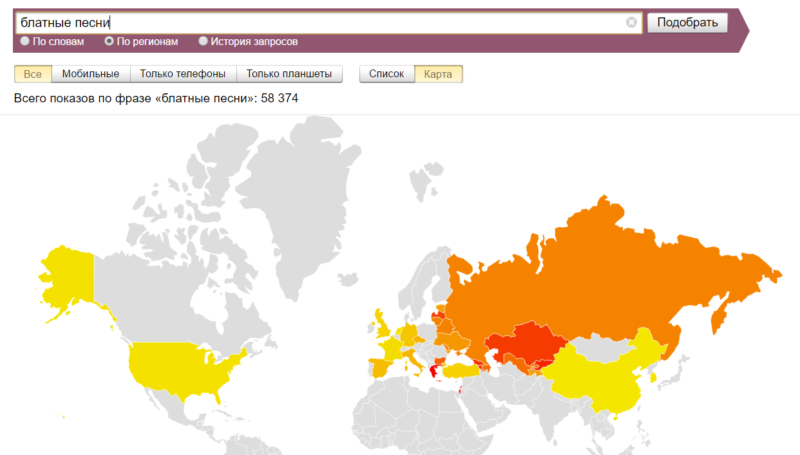
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:
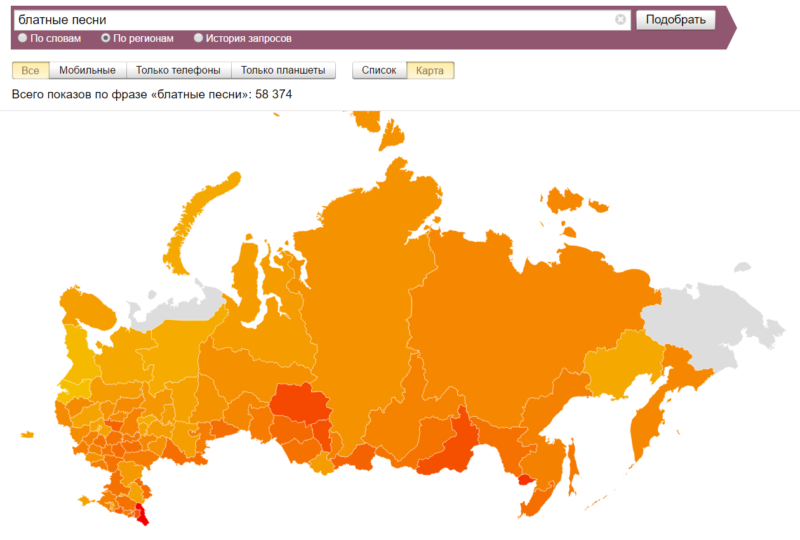
А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:
История запроса
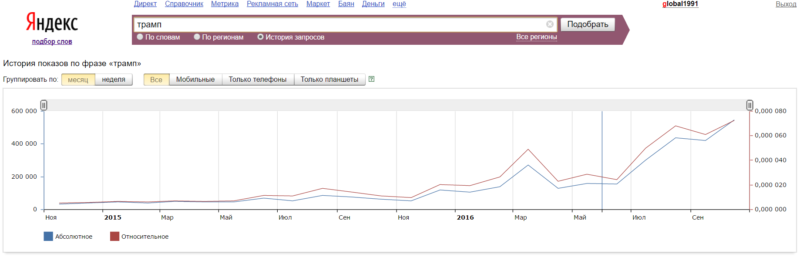
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:
Но самое профессиональное начинается, когда вы работаете с операторами.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
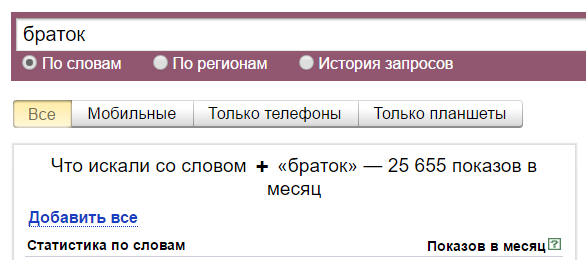
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.
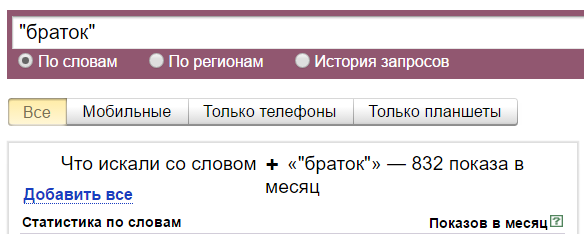
С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.
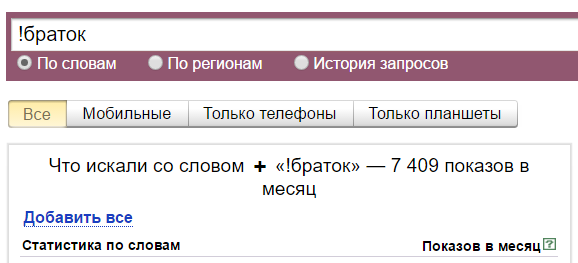
А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».
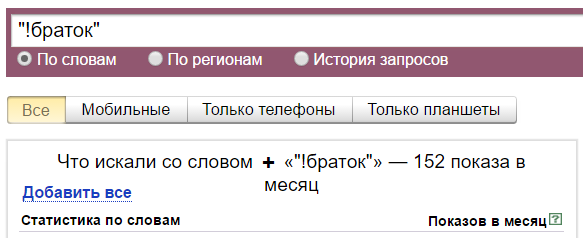
Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
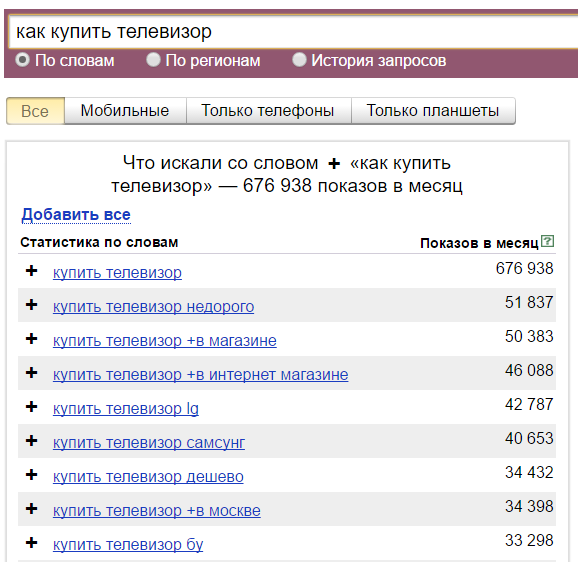
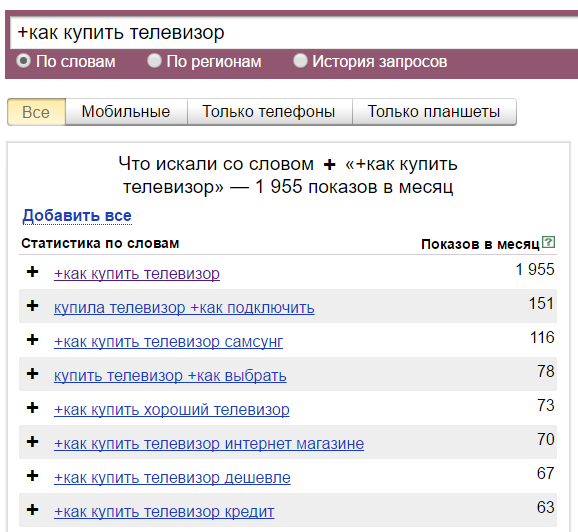
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:
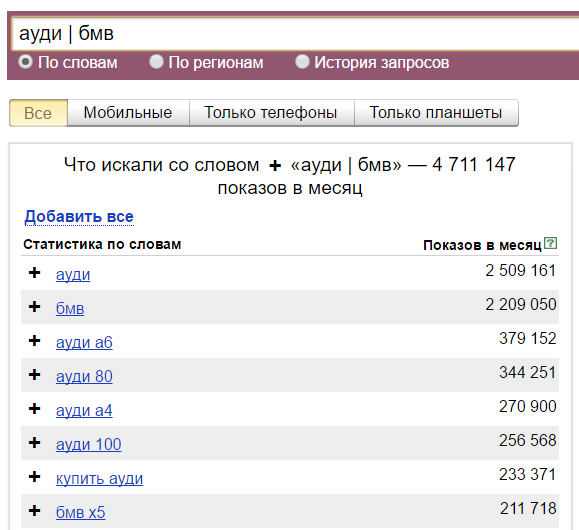
Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.
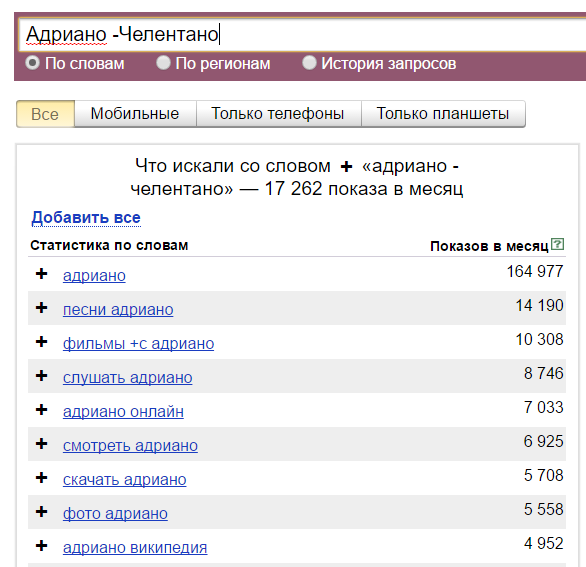
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
Круглые скобки «()» — группирует использование нескольких операторов.
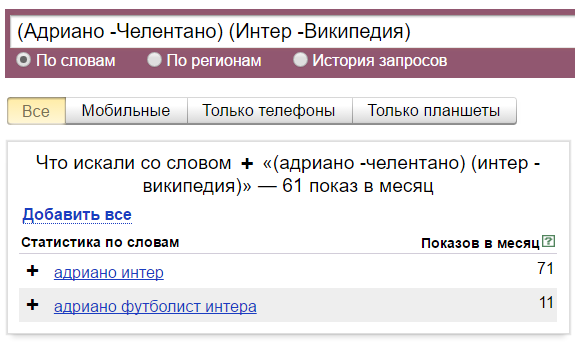
Квадратные скобки «[]» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:
Как видим, с неправильным порядком фразу почти никто не вводит:
Подбор ключевых слов в Google
Перейдем на другой сервис поиска ключевых слов — Google Keyword Planner. Мне этот сервис больше всего нравится, так как он выдает всевозможные варианты настройки поиска нужных слов и разные их варианты, разбитые по группам.
После авторизации вы попадете на примерно такую страничку (вверху экрана нужно перейти в Инструменты, если не перешли сразу):

Здесь вы можете начать поиск ключевых слов по фразе, сайту или категории, посмотреть статистику запросов и трендов или начать искать ключевые слова на основе существующих списков.
Сейчас предлагаю воспользоваться первым пунктом — «Поиск ключевых слов по фразе, сайту или категории». Нажимайте на эту фразу и вам откроется окошко с настройками:
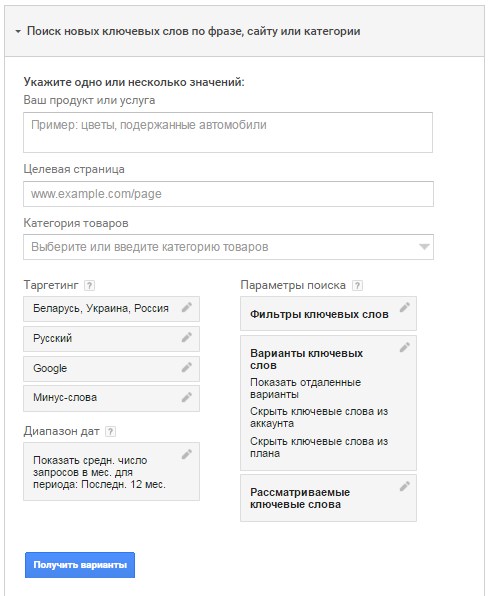
Ваш продукт или услуга: введите название вашего продукта (к примеру тот же «вязаный плед»).
Категория товаров: здесь вы можете выбрать категорию, к которой относится ваш товар. В каждой категории есть подкатегории. Если мы уже начали работать с вязаным пледом, то выберем для этого примера категорию «Дом и сад» и подкатегорию «Постельное белье» и еще одну под-подкатегорию «Одеяла и покрывала». Можно остановиться и на «Постельном белье». Это поле можно оставить пустым, если хотите увидеть полную картину поиска вашего пледа.
Таргетинг: здесь вы должны указать, какая аудитория вас интересует, чьи запросы вы хотите изучить (страна, язык).
Следующее поле с выбором поисковой системы лучше выбрать и поисковые партнеры, таким образом выдача ключевых слов будет шире.
Минус-слова: слова, которые вы хотите исключить из поиска, которые вас не интересуют. Например, вы вяжете плед спицами, а не крючком. Поэтому слово «крючок» или «крючком» нужно исключить.
Диапазон дат: здесь вы выбираете для себя удобный диапазон. Например, ваш плед более актуален в холодные месяцы, поэтому и диапазон дат выбираете соответственно, когда этот плед чаще всего ищут.
Параметры поиска
Фильтры ключевых слов: этот блок используется для настройки контекстной рекламы. Но в самом низу выпадающего мини-окошка вы можете заметить уровень конкуренции. Если выбрать высокий уровень конкуренции, то Google предложит вам поисковые запросы с огромным количеством предложений, то есть для вас там будет высокая конкуренция. При выборе низкой конкуренции, система выдаст вам поисковые запросы, по которым в сети мало предложений и велика вероятность попасть на глаза вашей аудитории.
Варианты ключевых слов: здесь все интуитивно понятно. Обычно я выключаю только «Показать варианты только для взрослых». С этими настройками можно поиграться в процессе.
Все! Нажимаем «Получить варианты» и получаем такую картину:

Вверху экрана вы видите свой поисковый запрос (название продукта) и выбранную категорию. В левой части экрана все параметры, которые вы выбирали (их можно менять, не покидая этой страницы). А в центре вы видите полученные результаты.
Сначала на глаза попадается график динамики поисковых запросов того ключевого слова, которое вы ввели. Здесь вы снова можете заметить, что летом вязаные пледы не так актуальны, как в октябре и ноябре (больше всего запросов).
Ниже Google предлагает вам варианты групп ключевых запросов с разным уровнем конкуренции. Каждая из групп содержит какое-то количество ключевых слов (это количество указано в скобках рядом с названием). Вы можете нажать на название группы (синее название — активная ссылка) и посмотреть детальнее.
Например, на рисунке выше вы видите группы слов, которые уже вам не интересны («флисовый», возможно, «покрывало»).
Открываете интересующую вас группу и начинаете выбирать для себя подходящие слова. Например, группа «вязание».

Здесь вы видите 5 вариантов ключевых запросов, и самый первый «вязаные пледы». Вам подходит это? Подходит! Напротив этого слова справа в этой же таблице вы видите стрелочки «Добавить в план». В правой странице экрана вы будете видеть все данные о своем плане. Чтобы вернуться на предыдущую страницу, просто нажмите стрелочку «назад».
Когда вы выбрали все интересующие вас ключевые слова, нажмите на кнопку «Загрузить» (над таблицей справа). У вас появится окошко, где вы отмечаете «Сохранить в Excel» или/и сохранить на Google Диске. Сохраните файл на своем компьютере.
Подобные подборки ключевых слов вы можете делать для разных групп товаров, по разным регионам, на разных языках (у кого мультиязычные магазины). Для этого вам нужно только менять критерии поиска в правой части экрана.
Типы вхождения ключевых слов
Для такого показателя, как читабельность, большое значение имеет использование разных вариаций фраз — помните это при подборе ключевых слов для сайта.
Вот перечень возможных типов вхождения ключевых фраз в тело текста:
Точное вхождение (его еще называют чистым)
Ключ используется в том виде, в каком он поступил. Без каких-либо знаков препинания, предлогов, иных окончаний и прочего.
К примеру, ключ в точном виде выглядит так: «обслуживание принтеров». Тогда в контексте он может быть использован таким образом: «У нас организовано быстрое и качественное обслуживание принтеров по очень привлекательным ценам».
Так называемое прямое вхождение
Род и падеж не меняются, лишь добавляются знаки препинания в контексте. Например, фраза «спортбары в Санкт-Петербурге» в тексте может прозвучать так: «Стоит признать, спортбары в Санкт-Петербурге — явление весьма популярное».
Вхождение с разбавлением
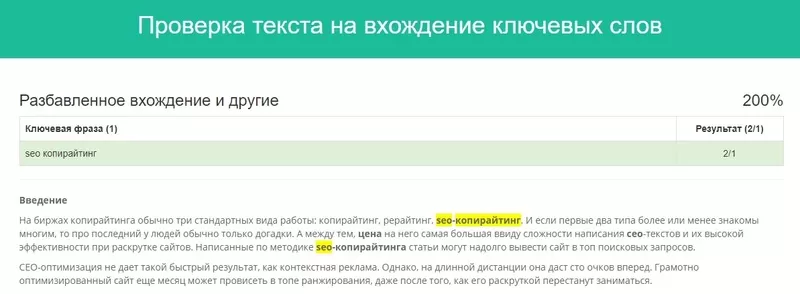
То есть к фразе-ключу добавляются еще слова. Например, если есть фраза «купить часы», то в контексте это может выглядеть так: «Ассортимент в магазине очень широкий, здесь вы сможете купить стильные часы по привлекательной цене».
Использование разных морфологических форм
Проще всего поменять форму слова. Пример для фразы «билеты в оперу»: «За билетами в оперу большой очереди не было».
Использование синонимов
Здесь подойдут не только синонимы, но и жаргонные фразы, аббревиатуры и прочее. Для ключа «рестораны СПб» контекстное упоминание может быть таким: «Столики в ресторанах Санкт-Петербурга перед Новым годом лучше бронировать заранее».
Так называемое обратное вхождение
Имеется в виду простая перемена слов местами. Было «купить телевизор», а стало «телевизор купить».
Вхождение с использованием разных типов (сложное)
Здесь применяются сразу несколько из приведенных выше вариантов. Для примера такая фраза: «купить конфеты в Екатеринбурге». В тексте можно сформулировать так: «В Екатеринбурге можно приобрести конфеты от разных производителей». Тут и синоним, и обратное вхождение, и дополнение. Опять же можно написать «андроид», а можно «android».
Букварикс
Сервис Букварикс предоставляет набор инструментов для работы с ключевыми словами и доменами, а также для работы со списками.
Возможности Букварикс:
- Поиск по ключевым словам (по одному слову или по списку);
- Поиск по заданному домену;
- Сравнение доменов (двух, нескольких).
- Приведение слов в списке к одному виду;
- Анализ слов в списке по частоте встречаемости (в порядке снижения частоты);
- Сравнение двух списков и формирование одного общего списка оригинальных ключевых слов;
- Комбинирование и формирование словосочетаний из ключевых слов двух списков;
- Поиск и удаление дубликатов слов из списка.
Тарифы:
- Без регистрации – бесплатно (с ограниченными возможностями);
- Бесплатный аккаунт – бесплатно (с ограниченными возможностями);
- Бизнес-аккаунт – 695 рублей за 1 месяц.
Описание
Wordstat Yandex или Подбор слов — это бесплатный сервис Яндекса, предназначенный для оценки пользовательского интереса к различным тематикам и подбора ключевых слов для SEO-оптимизации и контекстной рекламы. Кроме того, с помощью Яндекс Вордстат можно оценить сезонность и географическую зависимость поисковых запросов.
Особенности работы сервиса
- Wordstat не работает без регистрации. Ранее такая возможность была, однако с недавних пор инструмент запускается только после авторизации в Яндекс. Почте.
- Вордстат фильтрует пользователей. Под фильтры системы можно попасть из-за нарушения лицензии на использование Яндекса, а также из-за DDOS-атак на сервис с вашего компьютера в результате деятельности вируса. Стоит отметить, что в качестве атаки на сервер может быть воспринята работа специальных парсеров – программ, собирающих ключевые словосочетания в автоматическом режиме (например, Key Collector).
- Периодически при работе может выскакивать Captcha, приостанавливающая работу с Вордстатом. Возникает это из-за некорректного IP-адреса (для пользователей из не постсоветских стран), закрытых файлов cookie или отсутствии поддержки JS-скриптов на компьютере.
В Яндекс Wordstat доступны срезы по типам устройств пользователей:
- Срез «Десктопы» для запросов, введенных с компьютеров и ноутбуков,
- Срез «Мобильные» для запросов, введенных с планшетов и смартфонов,
- Срез «Только телефоны» – запросы исключительно со смартфонов,
- Срез «Только планшеты» – запросы, введенные только с планшетов.
Операторы Вордстат
- Оператор «-» (минус-слово). Позволяет исключить слово из статистики запросов. Применяется отдельно для каждого слова. Чтобы исключить словосочетание, необходимо добавлять оператор минус перед каждым словом в поисковой строке сервиса.
- Оператор «+» (учет стоп-слов). Позволяет учитывать в статистике союзы и предлоги во всех словоформах, которые игнорируются поисковой системой. При детализации запроса (левая колонка) оператор «+» по умолчанию используется во всех фразах, содержащих стоп-слова.
- Оператор «|» (логическое «или»). Позволяет получить статистику одновременно по нескольким условиям. Работает по правилу логического «или».
- Оператор «()» (логическое «и»). Необходим для группировки запросов, а в паре с оператором «|» позволяет создать регулярное выражение и получить список поисковых фраз по комбинации условий.
- Оператор «» (словоформа). В данном случае фиксируется запрос, поэтому из статистики удаляются дополнительные слова. Учитываются различные окончания, стоп-слова, но не учитывается порядок слов.
- Оператор «!» (точное вхождение). Его использование запускает фиксацию словоформы, т.е. будет учтена фраза только с текущим окончанием слов, но не учитывается порядок слов в запросе.
- Оператор «[]» (учет порядка слов). Необходим чтобы зафиксировать порядок слов в запросе. При этом будут учитываться словоформы и стоп-слова.
Онлайн парсеры
Подобные сервисы появились относительно недавно. Их преимущество – не нужно скачивать и устанавливать локально программные комплексы. Это экономит время, но сказывается на точности выборки КС. Причина – онлайн-парсеры не работают напрямую с базами данных Wordstat, а периодически скачивают их. Недостаток – не все запросы попадают в информационное поле сервиса.
Букварикс онлайн версия
Первым онлайн-сервисом с расширенными возможностями для SEO-оптимизаторов стал «Букварикс». До недавнего времени его использование было полностью бесплатным. Но с вводом нового функционала появилась платная подписка. Ее преимущества – фильтрация по частотности, количеству символов и слов. Есть ограничения для незарегистрированных пользователей. Но эта процедура бесплатная, возможна авторизация через социальные сети.
Особенности работы с «Букварикс»:
- максимальное количество поисковых фраз – 300 для платной версии;
- возможность скачивания отчета в формате .csv;
- группировка словоформ;
- дополнительные инструменты – анализ доменов, нормализатор, дубликатор и комбинатор слов.
Сервис значительно уступает по возможностям аналогичным программам, но прост в использовании. Рекомендован для начинающих оптимизаторов.
Составление масок для парсинга
Начинаем подбор ключевых запросов с составления запросов для парсинга. Чаще всего это 2-словные, но иногда и 3-словные запросы, которые также называют «масками».
Эти запросы должны максимально коротко, но релевантно описывать ваши услуги или товары.
Предположим, вы предлагаете доставку еды. Подходящими для вас масками будут:
– доставка еды – еда на дом – еда в офис – заказать еду – доставка обедов и т. д.
В зависимости от ассортимента, вам также нужно охватить более точные запросы, например: доставка плова, заказать суши и т. д.
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!
Как правильно составить маски запросов?
Не стоит пренебрегать данным этапом сбора семантического ядра (СЯ), так как от него зависит полнота СЯ, охват кампании, средняя цена за клик, количество и стоимость конверсий.
Неопытные специалисты часто используют только самые очевидные запросы. И хотя они охватывают большую часть целевой аудитории, по этим запросам самая высокая конкуренция и, как следствие, цена клика.
Чтобы собрать максимальное количество непересекающихся запросов, используйте:
- Брейншторминг. Просто подумайте, с помощью каких запросов ваша целевая аудитория может искать ваши товары или услуги.
- Правая колонка Yandex Wordstat. У Яндекса большой объем статистики, что и как ищут пользователи, и часто предлагает хорошие варианты ключевых фраз, до которых мы сами не додумались бы. Этот способ подходит и для сбора семантического ядра под Google;
- Блок «Вместе с этим ищут» на поиске Google и Яндекс. Работает по той же логике, что и правая колонка Wordstat — показывает, какие еще запросы вводят пользователи, которые ищут по определенному запросу.
- Сайты конкурентов. Просмотрите сайты ваших топ 5-10 конкурентов в Google и Яндекс. Подходящие нам ключевые запросы часто можно обнаружить в заголовках или в тексте на продвигаемых страницах.
- Названия конкурентов. В некоторых нишах, при правильном подходе, хорошие результаты показывает реклама на бренд конкурентов. Например, если вы занимаетесь доставкой пиццы, то в качестве ключевых фраз можете попробовать использовать « додо пицца» или «доминос».
- Ключевые слова конкурентов. Есть специальные сервисы конкурентного анализа, которые предлагают показать, какие запросы используют ваши конкуренты. Точность этих сервисов оставляет желать лучшего, но иногда помогают найти новые, релевантные запросы. Мы пользуемся keys.so, как недорогим и достаточно функциональным сервисом.
- Нестандартные формулировки, транслитерация, сленг. Иногда один и тот же бренд люди пишут по разному и, чтобы охватить их, нам нужно использовать все эти варианты в качестве ключевых слов. Например, вы продаете запчасти для автомобилей Hyundai. Чтобы охватить целевую аудиторию полностью, в вашем семантическом ядре должны использоваться слова: Хундай, Хендай, Хёндай, Хюндай, Хьюндай.

Блок «Вместе с этим ищут» в Яндексе

Правая колонка Яндекс Вордстат с рекомендациями ключевых слов
Подбор ключевых слов для сайта через Яндекс или Гугл: пошаговая инструкция
Шаг 1. Формируем базу.
Для начала нужно выяснить, каких разделов не хватает на вашем сайте. В этом может помочь анализ конкурентов. Расставьте разделы ресурса по их приоритету, после чего начинайте подбирать основные ключевые слова.
К примеру, вы занимаетесь изготовлением тортов. Примерные ключи будут следующими:
- кондитерский магазин;
- изготовление тортов на заказ;
- торты по виду: бисквитные, вафельные, песочные и т.п.;
- торты по названию: «Киевский», «Медовик», «Наполеон» и т.д.;
- торты к празднику: на день рождения, 23 февраля, 8 Марта и проч.;
- торты по весу: 500 г, 1 кг, 2 кг и т. д.
Шаг 2. Расширяем семантическое ядро.
Поиск подходящих ключей включает в себя определение большого количества фраз конкретной тематики на каждую страницу. Не обязательно это делать самостоятельно, автоматический подбор ключевых слов для сайта осуществляют Яндекс. Вордстат и «Планировщик ключевых слов» от Google.
Шаг 3. Дополняем семантическое ядро.
- Ищем синонимы.
- Просматриваем сервис статистики. Включаем в подбор те ключевые слова, с помощью которых пользователи уже попадали на ваш ресурс.
Знакомимся с фразами, которые поисковик выдает в виде подсказок при вводе запроса. Больше половины из них, введенные пользователями Яндекса в течение месяца, являются оригинальными и не отображаются в Вордстате.
- Просматриваем блок внизу поисковика: «Вместе с … ищут».
- С помощью семантического анализа текстов выясняем, какие ключевые слова подобрали для своего сайта конкуренты. Тут помогут сервисы Advego и Etxt.
Шаг 4. Отфильтровываем все лишнее:
Завершая подбор ключевых слов для сайта, проверьте на соответствие выдаче некоммерческие запросы: к примеру, не «заказать торт», а «праздничный торт».
Под информационный запрос можно написать специальную статью или вообще исключить его из списка «запрос – страница».
Вас также может заинтересовать: Инструменты аналитики сайта
Особенности учета словоформ Вордстата
Объединение словоформ. Фразы считаются словоформами, если это:
- Склонения числительных падежам (три, трех, трем, тремя);
- Склонения существительных по падежам и числам (слон, слоны, слонами, слонов);
- Изменения суффиксов у глаголов (бежать, бежит);
- Причастия, деепричастия, глаголы и их спряжения (просмотреть, просмотрел, просмотревший, просмотренный);
- При изменении «ё» на «е» и наоборот (елка,ёлка);
- Числа, падежи, форма и степень прилагательных (высокий, выше, высочайший).
В некоторых случаях количество запросов может отличаться из-за учета фраз, характерных только для одной из них:

Например, слово «тертый» появляется при поиске по запросу «три», но не показывается по запросу «трех». Не стоит забывать, что эта особенность характерна только для общей (базовой) частотности. Чтобы получить точное значение необходимо использовать оператор «точное вхождение» (восклицательный знак).
Разделение словоформ. Фразы не считаются словоформами, если это:
- Ошибки в словах (витамины, ветамины);
- Синонимы (чашка, кружка, стакан);
- Сленг или жаргон (препод, преподаватель);
- Транслитерация (яндекс, yandex);
- Сложносоставные слова (электроинструмент, электро инструмент);
- Глаголы, образованные за счет приставок (ехать, приехать, заехать);
- Уменьшительно-ласкательные формы (машина, машинка);
- Существительные, имеющие разный род (собака, пес);
- Числительные с одним значение, но разным написанием (10, десять, десятый);
Алгоритм составления семантического ядра
Семантическое ядро – это список всех ключевых фраз, по которым осуществляется продвижение. Мы поговорили о классификации запросов, правилах отбора, инструментах. Теперь нужно разобраться, как составить семантическое ядро.
Подумайте, как Ваши товары и услуги могут искать в поисковых системах. Соберите популярные запросы в Вашей тематике через сервис Яндекс.Вордстат
Обращайте внимание на запросы в правой колонке, поисковые подсказки в результатах поиска. Используйте жаргонные выражения, чтобы найти неочевидные запросы, словари синонимов, «народные» обозначения Ваших товаров или услуг.
Через Сеопульт посмотрите запросы конкурентов, сайты которых имеют высокую посещаемость
Отберите среди запросов конкурентов те, которые подходят для Вашего проекта.
Соберите все запросы в одном файле Excel, отсортируйте по алфавиту и удалите дубли. Запросы, имеющие неправильную структуру и порядок слов с точки зрения русского языка, рекомендую привести в нормальный вид.
Проверьте частоту запросов в кавычках. Если запросов много, используйте инструмент Топвизор. Удалите из списка запросы с нулевой частотой в кавычках.
Проверьте полученный список запросов еще раз. Удалите фразы, которые не подходят.
Полезный совет. Иногда конкуренты забывают закрывать доступ от систем статистики на своих сайтах. Если кто-то из конкурентов забыл закрыть доступ к своей статистике, посмотрите в ней, по каким запросам переходят на сайт конкурента.
Дополнительные возможности
На иллюстрации выше, цифрами отмечены: 1 — сам запрос, 2 — дата обновления статистики Яндекса по данным фразам, 3 — суммарное число показов по фразам которые соответствуют запросу, 4 — общее число показов по фразе.
Здесь очень важно не путать общее число показов из колонки 4 и число точных запросов по фразе, которое можно получить с использованием операторов «Кавычки», «Восклицательный знак» и «Квадратные скобки». К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны)
К дополнительным возможностям WordStat отнесем изучение истории (сезонности) спроса в тематике, получение частоты в заданном регионе и анализ популярности фраз в мобильном поиске (планшеты, мобильные телефоны).
Данные функции часто оказываются полезны при планировании рекламных кампаний.
История запроса
Можно быстро понять, как меняется интерес к выходу новой модели «IPhone 6S». К сожалению, в текущий момент история запросов не поддерживает операторы («ИЛИ», «Группировка», «Квадратные скобки»).
Изучение динамики по запросу . Хорошо видны резкие сезонные всплески и провалы после наступления января.
Частота в заданном регионе
Отдельного упоминания заслуживает получение частоты запроса в заданном регионе. С помощью разделения общей частоты запроса по регионам можно оценить как частоту заданного запроса в интересующей нас регионе (Москва, Москва и область, Санкт-Петербург и т.д.), так и относительную популярность того или иного запроса в регионе.
Из примера приведенного ниже видно, что запросы со словами «купить» и «Казань» преимущественно задают жители г. Казань, что весьма очевидно. Использование данной функции на практике иногда открывает и более неожиданные закономерности.
Сбор (парсинг) запросов заданной длинны
На практике бывает полезным использовать приём парсинга запросов заданной длинны (из 2, 3, 4 слов и так далее) с вхождением ключевого слова. Данная возможность оказывается особенно актуальной, если вы работаете в популярной тематике и сбор первых 41 страниц не позволяет получить все поисковые фразы.
Для сбора всех фраз с длиной в 3 слова используется конструкция вида:
«IPhone IPhone IPhone»
Данный запрос позволяет собрать уже не просто 41 страницу поисковых фраз произвольной длины, а 41 страницу фраз из трёх слов с вхождением «IPhone». Последовательный анализ запросов с длиной от 2 до 7 слов позволяет существенно увеличить охват целевой аудитории.
Для ускорения сбора частот, быстрого парсинга Яндекс.Вордстат и хранения целевых ядер, рекомендуется использовать программы и онлайн-сервисы автоматизации, к числу которых можно отнести «Пиксель Тулс». После быстрой настройки параметров сбора, можно получить широкое семантического ядро в рамках тематики.
Анализ проведён с помощью инструментов в сервисе Пиксель Тулс.
Детальный анализ словоформ для ВЧ-запросов
Для ВЧ-запросов длиной в 2 и более слов может пригодиться анализ частоты встречаемости словоформ. Для этого требуется ввести исходную фразу, скажем, «продвижение сайтов» и далее последовательно исключать точные популярные написания с помощью комбинации операторов вида — -«», что приводит к исключению наиболее частотной формы написания из статистики и появлению второй по популярности версии. Далее процедуру можно повторить.
Как работает генератор ключевых слов?
Генератор ключевых фраз представляет собой автоматизированное решение для создания новых ключевых слов и сочетаний на основе их перемножения в общую фразу. С его помощью построение списка ключевых фраз существенно ускоряется и упрощается. Пересечение слов происходит между всеми указанными столбцами, перечень формируется в режиме реального времени. Идеально подходит для парсинга, для Директа. Увеличение числа колонок, участвующих в пересечении комбинатором, производится простым нажатием на символ “+”. Пересекатор одновременно учитывает данные до 8 столбцов со словами, предельное ограничение числа полученных элементов – 100 000.
Используем поисковые операторы
С их помощью можно значительно сократить список запросов.
Плюс
Ввод «+» позволяет сделать стоящее за ним слово или словосочетание обязательным. Сервис не учитывает предлоги и союзы, такие как: из, от, на, для, и, в. Наглядный пример, в котором количество запросов уменьшилось в более, чем 13 раз.


Восклицательный знак
С помощью «!» фиксируется окончание слова, перед которым он поставлен. Этот оператор часто используется для оптовых продаж. Например, вы вводите «купить кухонные столы» и получаете более 60 тысяч показов
Но, обратите внимание, слово «столы» в статистике отображается и в единственном числе – «стол». Ставим оператор «!» и получаем чуть больше 6 тысяч показов


[] фиксируют расстановку слов в искомом запросе. Часто используется в логистике. Пример:

Кавычки
Поставив запрос в “”, вы получите данные по показам без добавления лишних слов. То есть, если вы вводите «ремонт мебели москва», то получаете статистику по запросам из трёх слов
Важно: чем ближе числовой показатель запроса с кавычками и без, тем лучше работает данный запрос. На этом примере видно, что запрос малоэффективен


Или
Обозначается при помощи вертикальной черты «|» и используется при сравнении или перемещении отдельных слов/словосочетаний.
Символы () дают возможность сгруппировать запросы или несколько операторов вместе.

Минус
Знак «-» необходим для того, чтобы убрать из статистики ненужные для вас слова (минус слова). С его помощью удаётся дать реальную оценку спроса на товар. Если вы занимаетесь производством и установкой каменных столешниц и только из натурального камня, то вам нужно исключить запросы типа «искусственный», «своими руками», «в домашних условиях», «агломерат» и так далее. В результате список запросов сократился почти на тысячу.