Файл robots.txt: создание, настройка, проверка и индексация сайта
Содержание:
Создание robots.txt для WordPress , Joomla и Ucoz
Различные CMS, получившие широкую популярность на просторах Рунета, предлагают пользователям свои версии файлов robots.txt. Некоторые из них не имеют таких файлов вовсе. Зачастую эти файлы либо слишком универсальны и не учитывают особенностей ресурса пользователя, либо имеют ряд существенных недостатков.
Опытный специалист может вручную исправить положение (при недостатке знаний так лучше не делать). Если вы боитесь копаться во внутренностях сайта, воспользуйтесь услугами коллег. Подобные манипуляции, при знании дела, занимают всего пару минут времени. Например, robots.txt WordPress может выглядеть таким образом:
 Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки. Единственный его недостаток — система создаст файл, спустя примерно месяц, после конструирования ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:
Файл robots.txt для Ucoz предоставляется автоматически. Он имеет оптимальные настройки. Единственный его недостаток — система создаст файл, спустя примерно месяц, после конструирования ресурса. Если неохота ждать, можно написать файл самостоятельно. Выглядеть он будет так:
 Joomla позволяет нескольким URL ссылаться на одну и ту же страницу. Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:
Joomla позволяет нескольким URL ссылаться на одну и ту же страницу. Поисковые системы примут такие настройки за дублирование контента. Избежать этого поможет установка robots.txt для Joomla следующего содержания:

В последних двух строчках, как несложно догадаться, нужно прописать данные собственного ресурса.

Настройка
Для грамотной настройки файла роботов нам нужно точно знать, какие из разделов сайта должны быть проиндексированы, а какие – нет. В случае с простым одностраничником на html + css нам достаточно прописать несколько основных директив, таких как:
User-agent: *
Allow: /
Sitemap: site.ru/sitemap.xml
Host: www.site.ru
Здесь мы указали правила и значения для всех поисковых систем. Но лучше добавить отдельные директивы для Гугла и Яндекса. Выглядеть это будет так:
User-agent: *
Allow: /
User-agent: Yandex
Allow: /
Disallow: /politika
User-agent: GoogleBot
Allow: /
Disallow: /tags/
Sitemap: site.ru/sitemap.xml
Host: site.ru
Теперь на нашем html-сайте будут индексироваться абсолютно все файлы. Если мы хотим исключить какую-то страницу или картинку, то нам необходимо указать относительную ссылку на этот фрагмент в Disallow.
Вы можете использовать сервисы автоматической генерации файлов роботс. Не гарантирую, что с их помощью вы создадите идеально правильный вариант, но в качестве ознакомления можно попробовать.
Среди таких сервисов можно выделить:
- PR-CY,
- htmlweb.
С их помощью вы сможете создать robots.txt в автоматическом режиме. Лично я крайне не рекомендую этот вариант, потому как намного проще сделать это вручную, настроив под свою платформу.
Говоря о платформах, я имею ввиду всевозможные CMS, фреймворки, SaaS-системы и многое другое. Далее мы поговорим о том, как настраивать файл роботов WordPress и Joomla.
Но перед этим выделим несколько универсальных правил, которыми можно будет руководствоваться при создании и настройке роботс почти для любого сайта:
Закрываем от индексирования (Disallow):
Открываем (Allow):
- картинки;
- JS и CSS-файлы;
- прочие элементы, которые должны учитываться поисковыми системами.
Помимо этого, в конце не забываем указать данные sitemap (путь к карте сайта) и host (главное зеркало).
Что такое файл robots txt, зачем он нужен и за что он отвечает
 Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Файл robots txt, это текстовый файл, который содержит инструкции для поисковых роботов. Перед обращением к страницам Вашего блога, робот ищет первым делом файл robots, поэтому он так важен. Файл robots txt это стандарт для исключения индексации роботом тех или иных страниц. От файла robots txt будет зависеть попадание в выдачу Ваших конфиденциальных данных. Правильный robots txt для сайта поможет в его продвижении, поскольку он является важным инструментов во взаимодействии Вашего сайта и поисковых роботов.
Не зря файл robots txt называют важнейшим инструментом SEO, этот маленький файл напрямую влияет на индексацию страниц сайта и сайта в целом. И наоборот, неправильный robots txt может исключить некоторые страницы, разделы или сайт в целом из поисковой выдачи. В этом случае можно иметь и 1000 статей на блоге, а посетителей на сайте просто не будет, будут чисто случайные прохожие.
На Яндекс вебмастере есть обучающее видео, в котором Яндекс сравнивает файл роботс тхт с коробкой Ваших личных вещей, которые Вы не хотите никому показывать. Чтобы посторонние не заглядывали в эту коробку, Вы её заклеиваете скотчем и пишете на ней – «Не открывать».
Роботы, как воспитанные личности, эту коробку не открывают и другим не смогут рассказать, что там находится. Если файла robots txt нет, то робот поисковой системы считает, что все файлы доступные, он откроет коробку, всё посмотрит и другим расскажет, что лежит в коробке. Чтобы робот не лазил в этот ящик, надо запретить ему туда лазить, делается это с помощью директивы Disallow, что переводится с английского – запретить, а Allow – разрешить.
Это обычный txt файл, который составляется в обычном блокноте или программе NotePad++, файл, который предлагает роботам не индексировать определённые страницы на сайте. Для чего это нужно:
- правильно составленный файл robots txt не позволяет роботам индексировать всякий мусор и не забивать поисковую выдачу ненужным материалом, а также не плодить дубли страниц, что является очень вредным явлением;
- не позволяет роботам индексировать информацию, которая нужна для служебного пользования;
- не позволяет роботам шпионам воровать конфиденциальные данные и использования их для отправки спама.
Это не означает, что мы что-то хотим спрятать от поисковиков, что-то тайное, просто эта информация не несёт ценности ни для поисковиков, ни для посетителей. Например, страница логина, RSS ленты и т.д. Кроме того, файл robots txt указывает зеркало сайта, а также карту сайта. По умолчанию на сайте, который делается на WordPress, файла robots txt нет. Поэтому нужно создать robots txt файл и залить его в корневую папку Вашего блога, в данной статье мы рассмотрим robots txt для WordPress, его создание, корректировку и заливку на сайт. Итак, сначала мы узнаем, где находится файл robots txt?
Правильные файлы robots.txt для популярных CMS
Пример Robots.txt для WordPress
Ниже вы можете увидеть мой вариант с данного Seo блога.
User-agent: Yandex Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Host: romanus.ru User-agent: * Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /tag Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: */comments/ Disallow: /?feed= Disallow: /?s= Sitemap: https://romanus.ru/sitemap.xml
Трэкбэки запрещаю потому что это дублирует кусок статьи в комментах. А если трэкбэков много — вы получите кучу одинаковых комментариев.
Служебные папки и файлы любой CMS я стараюсь я закрываю, т.к. не хочу чтобы они попадали в индекс (хотя поисковики уже и так не берут, но хуже не будет).
Фиды (feed) стоит закрывать, т.к. это частичные либо полные дубли страниц.
Теги закрываем, если мы их не используем или нам лень их оптимизировать.
Примеры для других CMS
Чтобы скачать правильный robots для нужной CMS просто кликните по соответствующей ссылке.
- Robots.txt для Joomla;
- Opencart;
- DLE;
- Bitrix;
Используемые директивы
User-agent
Все блоки правил начинаются с директивы User-agent, в которой указывается название робота, для которого задается правило. Запись вида User-agent: * означает, что правило задается для всех поисковых роботов.
Например, при следующей записи правило будет применено только к основному индексирующему боту Яндекса:
User-agent: YandexBot
Правило будет применено ко всем роботам Яндекса и Google:
User-agent: Yandex User-agent: Googlebot
Правило будет применено вообще ко всем роботам:
User-agent: *
Disallow и Allow
Директивы используются, чтобы запретить и разрешить доступ к определенным разделам сайта.
Например, можно запретить индексацию всего сайта (Disallow: /), кроме определенного каталога (Allow: /catalog):
User-agent: имя_бота Disallow: / Allow: /catalog
Запретить индексацию страниц, начинающихся с /catalog, но разрешить для страниц, начинающихся с /catalog/auto и /catalog/new:
User-agent: имя_бота Disallow: /catalog Allow: /catalog/auto Allow: /catalog/new
В каждой строке указывается только одна директория. Для запрещения (или разрешения) доступа к нескольким каталогам, для каждого требуется отдельная запись.
С помощью Disallow можно ограничить доступ к сайту для нежелательных ботов, тем самым снизив создаваемую ими нагрузку. Например, чтобы запретить доступ ко всему сайту для MJ12bot и AhrefsBot — ботов сервиса majestic.com и ahrefs.com — используйте:
User-agent: MJ12bot User-agent: AhrefsBot Disallow: /
Аналогичным образом устанавливается блокировка и для других ботов (скажем, DotBot, SemrushBot и других).
Примечания:
- Пустая директива Disallow: равнозначна Allow: /, то есть «не запрещать ничего».
- В директивах может использоваться символ $ для обозначения точного соответствия указанному параметру. Например, запись Disallow: /catalog аналогична Disallow: /catalog * и запретит доступ ко всем страницам с /catalog (/catalog, /catalog1, /catalog-new, /catalog/clothes и др.).Использование $ это изменит. Disallow: /catalog$ запретит доступ к /catalog, но разрешит /catalog1, /catalog-new, /catalog/clothes и др.
Sitemap
При использовании файла sitemap.xml для описания структуры сайта, можно указать путь к нему с помощью соответствующей директивы:
User-agent: * Disallow: Sitemap: https://mydomain.com/путь_к_файлу/mysitemap.xml
Можно перечислить несколько файлов Sitemap, каждый в отдельной строке.
Host
Директива используется для указания роботам Яндекса основного зеркала сайта и полезна, когда сайт доступен по нескольким доменам.
User-agent: Yandex Disallow: /catalog1$ Host: https://mydomain.com
Примечания:
- Директива Host может быть только одна; если в файле указано несколько, роботом будет учтена только первая.
- Необходимо указывать протокол https, если он используется. Если вы используете http, зеркало можно записать в виде mydomain.com
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Crawl-delay
Директива устанавливает минимальный интервал в секундах между обращениями робота к сайту, что может быть полезно для снижения создаваемой роботами нагрузки. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами (разделитель — точка).
User-agent: Yandex Disallow: Crawl-delay: 0.5
Примечания:
- Для корректного прочтения директивы, ее нужно указывать в блоке правил User-agent после директив Disallow и Allow.
Clean-param
Директива используется для робота Яндекса. Она позволяет исключить из индексации страницы с динамическими параметрами в URL-адресах (это могут быть идентификаторы сессий, пользователей, рефереров), чтобы робот не индексировал одно и то же содержимое повторно, повышая тем самым нагрузку на сервер.
Например, на сайте есть страницы:
www.mydomain.ru/news.html?&parm1=1&parm2=2 www.mydomain.ru/news.html?&parm2=2&parm3=3
По факту по обоим адресам отдается одна и та же страница — www.mydomain.ru/news.html, при этом в URL присутствуют дополнительные динамические параметры.
Чтобы робот не индексировал каждую подобную страницу, можно использовать директиву:
User-agent: Yandex Disallow: Clean-param: parm1&parm2&parm3 /news.html
Через знак & указываются параметры, которые робот должен игнорировать. Далее указывается страница, для которой применяется данное правило
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
Как проверить файл?
Для этих целей лучше использовать специальные сервисы от Yandex и Google, т. к. эти поисковые системы являются наиболее популярными и востребованными (чаще всего единственно используемыми), такие поисковики как Bing, Yahoo или Rambler рассматривать нет смысла.
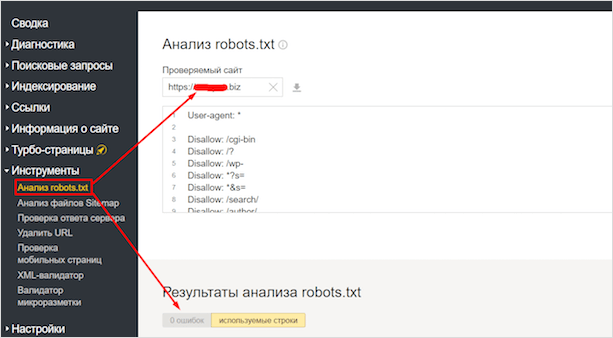
Для начала рассмотрим вариант с Яндексом. Заходим в Вебмастер. После чего в Инструменты – Анализ robots.txt.
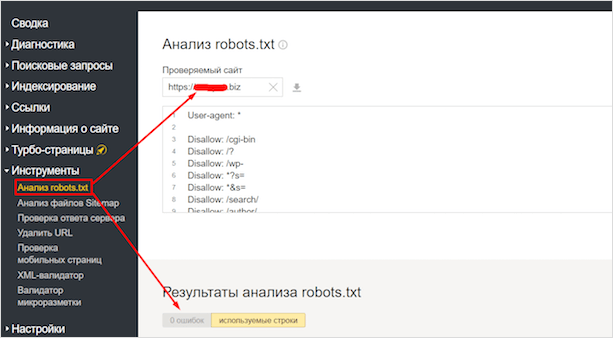
Здесь вы сможете проверить файл на ошибки, а также проверить в реальном времени, какие страницы открыты для индексации, а какие – нет. Весьма удобно.
У Гугла есть точно такой же сервис. Идем в Search Console. Находим вкладку Сканирование, выбираем – Инструмент проверки файла robots.txt.
Здесь точно такие же функции, как и в отечественном сервисе.
Обратите внимание, что он показывает мне 2 ошибки. Связано это с тем, что Гугл не распознает директивы очистки параметров, которые я указал для Яндекса:. Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Обращать внимание на это не стоит, т. к
роботы Google используют только правила для GoogleBot.
Настройка через хостинг и плагин
Если вы создаете файл самостоятельно, то для работы с ним рекомендуется использовать текстовый редактор, который не добавляет лишний код в разметку, например, Notepad++.
Основные директивы, которые понадобятся в настройке robots.txt через хостинг или плагин, например, Yoast SEO — выглядят следующим образом:
- User-agent: — указывает к каким поисковым роботам применяется правило, например, Yandex, * (роботы всех ПС), Googlebot;
- Disallow: — запрещает индексацию;
- Allow: — индексация разрешена;
- Sitemap: — указывает на расположение файла sitemap.xml. В данном файле содержатся все страницы, предназначенные для индексирования;
- Host: — указывает на главное зеркало сайта, например, https://домен.ru/. В данный момент, директива Host не используется и прописывать ее в файле robots.txt — не надо.
Как запретить индексирование сайта в robots.txt
Чтобы запретить индексирование сайта в robots.txt для всех поисковых роботов, используйте следующую конструкцию:
User-agent: * Disallow: /
robots для блога/сайта на WordPress
Файл robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: /*?* Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Для WooCommerce
Файл robots.txt для WooCommerce выглядит следующим образом:
User-agent: * Disallow: /cgi-bin Disallow: /wp- Disallow: /tag Disallow: /wp-admin Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /tag Disallow: *?replytocom Disallow: *?* Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Disallow: /my-account/ Disallow: /wp-login.php Disallow: /wp-register.php Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://заменить на домен вашего сайта/sitemap.xml (если не используете плагин Yoast SEO) Sitemap: https://заменить на домен вашего сайта/sitemap_index.xml (если используете плагин Yoast SEO)
Готовый файл robots.txt загрузите на хостинг, в корень сайта или создайте его там через стандартный менеджер файлов и сохраните изменения.
Повторюсь, если редактируете robots.txt на компьютере или работаете с любым другим файлом, который содержит в себе код, то используйте для этого Notepad++.
Для примера, этот текст написан в OpenOffice и если его скопировать и вставить, например, в онлайн HTML-редактор, то увидите это:

Некоторые редакторы автоматически добавляют теги разметки в текст, а чтобы этого не происходило — используйте предназначенные для этого инструменты.
Настройка через плагин Yoast SEO
Если у вас установлен плагин Yoast SEO, то для создания и редактирования файла robots.txt в нем предусмотрена эта функция.
Для того,чтобы создать или редактировать — перейдите в настройки «SEO» и выберите пункт «Инструменты».

Если файла нет, то плагин предложит создать его.

Для этого нажмите на соответствующую кнопку «Создать файл robots.txt». В поле ниже автоматически появятся следующие строки:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php

Если вы хотите запретить поисковым роботам индексировать сайт на момент разработки, то измените содержимое на:
User-agent: * Disallow: /
Если вы готовы запустить проект, то настройте содержимое файла через редактор плагина.
Не забудьте сохранить настройки.
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Для настройки X-Robots-Tag необходимо иметь минимальные навыки программирования и доступ к файлам .php или .htaccess вашего сайта. Директивы тега meta robots также применимы к тегу x-robots.
<?
header("X-Robots-Tag: noindex, nofollow");
?>
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt», название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами —
http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает
стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылка
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Когда не стоит прибегать к robots.txt
При грамотном использовании данный файл несёт пользу, но есть ситуации, в которых его применение в целях блокировки краулинга только мешает.
Блокировка Javascript/CSS
Поисковым системам необходим доступ ко всем ресурсам, чтобы корректно рендерить страницы — это необходимая часть ранжирования. Если же, к примеру, Javascript, оказывающий подчас определяющее влияние на функционал страницы и пользовательский опыт отключен, это может привести к плохим результатам вплоть до понижения в выдаче.
Например, если ваша страница содержит редиректы с помощью Javascript, а тот, в свою очередь, закрыт от индексации, робот распознает в таком перенаправлении клоакинг — подмену страницы.
Блокировка по URL
Robots.txt можно использовать для блокировки URL со специфическими параметрами, но это далеко не всегда верное решение. Правильная настройка robots,txt предполагает использование Google Search Console — такой способ будет приемлем с точки зрения поисковых систем.
Можно разместить информацию в самом URL — /items#filter=date, так как краулеры не считывают это. Если URL-параметр должен быть использован обязательно, ссылка может содержать rel=nofollow во избежание индексации.
Блокировка URL с обратными ссылками
Если обратные ссылки запрещены robots.txt, поисковый робот не сможет перейти по ссылкам с других сайтов на ваш ресурс. Из-за этого ваш сайт не получит баллов ранжирования и опустится в выдаче.
Установка правил против краулеров соцсетей
Даже если вы не хотите, чтобы поисковые системы читали ваши страницы, возможно, доступ роботов соцсетей не помешает. Ведь они формируют сниппеты в случае репоста ваших страниц в соцсети. Например, Facebook будет пытаться зайти на каждую страницу, которую постят в нём, чтобы отображать релевантный сниппет.
Блокировка доступа к сайтам в процессе разработки
Использование robots.txt для блокировки всего сайта в процессе разработки хорошо работает. В то же время, Google рекомендует убирать из индексации страницы, но давать возможность роботу их читать. В целом же, следует делать такие сайты недоступными для посещения вообще.
Когда нечего блокировать
Некоторые сайты с весьма чистой архитектурой не испытывают потребности в блокировке каких-либо разделов. В такой ситуации вообще можно не создавать robots.txt, а возвращать страницу 404.
Эффективный маркетинг с Calltouch
- Анализируйте воронку продаж от показов рекламы до ROI от 990 рублей в месяц
- Отслеживайте звонки с сайте с точностью определения источника рекламы выше 96%
- Повышайте конверсию сайта на 30% с помощью умного обратного звонка
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Добавьте интеграцию c CRM и другими сервисами: более 50 готовых решений
- Контролируйте расходы на маркетинг до копейки
Узнать подробнее
Как создать правильный robots.txt
Правильный robots легко написать вручную, не прибегая к помощи различных конструкторов. Процесс сводится к прописыванию нужных директив в обычном файле блокнота, который, после внесения всех данных, сохраняется под названием «robots». Вам остаётся только закачать его в корневую директорию собственного ресурса. Для одного сайта нужен только один такой файл. В нем можно прописать инструкции для ботов всех нужных поисковых систем. То есть, делать отдельный файл под каждый поисковик не понадобится. Полноценный robots.txt пример может выглядеть так:

Теперь поговорим о том, что должно находиться внутри robots.txt. Обязательно употребление двух директив: User-agent и Disallow. Первая определяет, какому боту адресовано данное послание. Вторая показывает, какую страницу или директорию ресурса запрещено индексировать.
Чтобы задать одинаковые правила для всех ботов, можно в директиве User-agent вместо названия прописать символ: * (звездочку).
Файл robots.txt в таком случае будет выглядеть следующим образом:
Как можно догадаться, /file.html — это название конкретного файла, индексация которого запрещена. /papka/ — название директории, на содержимое которой не будет распространятся индексация.
Если нужно снять ограничения и разрешить индексацию всех страниц, файл следует изменить так:
Заключение
Итак, в данной статье мы рассмотрели вопрос, что собой представляет файл robots txt, выяснили, что этот файл является очень важным для сайта. Узнали, как сделать правильный robots txt, как адаптировать файл robots txt с чужого сайта к себе, как закачать его на свой блог, как его проверить.
Из статьи стало понятно, что новичкам, на первых порах, лучше использовать готовый и правильный robots txt, но надо не забыть заменить в нем в директории Host домен на свой, а также прописать адрес своего блога в картах сайта. Скачать мой файл robots txt можно здесь. Теперь, после исправления, можете использовать файл на своем блоге.
Отдельно по файлу robots txt есть сайт Вы можете зайти на него и узнать более подробную информацию. Надеюсь, у Вас всё получится и блог будет хорошо индексироваться. Удачи Вам!
P.S. Для правильного продвижения блога надо правильно писать о оптимизировать статьи на блоге, тогда на нём будет высокая посещаемость и рейтинги. В этом Вам помогут мои инфопродукты, в которые вложен мой трёхлетний опыт. Можете получить следующие продукты:
- пошаговый алгоритм написания мощных статей для блога;
- платная книга Как написать статью для блога;
- интеллект карта Пошаговый алгоритм создания блога (сайта) для новичков;
- платный видео-курс «Как написать и оптимизировать статью для блога. Продвижение блога статьями«.
Просмотров: 12487