Как составить семантическое ядро без помощи специалиста
Содержание:
Какими бывают поисковые запросы?
Остановимся на основных классификациях запросов, без которых не обойтись при составлении семантики.
Самая главная характеристика — это конкретность формулировки запроса, то есть запрос общий (нечёткий) или чёткий. Сравните: «купить смартфон xiaomi» и «москва аренда». Первый запрос обозначает желание пользователя приобрести смартфон определённого бренда, а во втором не ясно, что нужно арендовать: квартиру, офис, гараж или что-то другое.
Второй важный фактор — геозависимость. Поисковая система старается сразу понять, насколько удовлетворение запроса пользователя зависит от его локации. Сравним: «аренда велосипеда на сутки» и «заказать чехол из китая»
В первом случае поисковой системе важно показать региональные бизнесы. Во втором случае локация не так важна
Третий фактор — тип запроса. Запросы бывают информационными («как собрать семантическое ядро»), транзакционными («заказать seo-продвижение»), навигационными («сайт про seo и маркетинг seoforge») и брендовыми («поисковая оптимизация от seoforge»)
Важность типа запросов сложно переоценить: не стоит ждать высокой конверсии от информационных запросов и большого поискового объёма от брендовых, только если вы не Кока-Кола или Адидас.
Четвёртый фактор — частотность запроса, то есть как часто пользователи ищут что-то по этому запросу. Запросы бывают высоко-, средне- и низкочастотными. В каждой нише степень частотности определяется общим спросом. Получается, что в сфере покупки чехлов для телефона запрос будет низкочастотным, если его ищут меньше 1 000 раз в месяц, а в сфере продажи станков 1 000 показов — это уже высокая частотность. Всё относительно в этом мире, но если брать общую температуру по больнице, то получается следующее:
- <1 000 — низкочастотные,
- 1 000–10 000 — среднечастотные,
- >10 000 — высокочастотные.
Пятый фактор — структура запроса, — сугубо технический, но на нём важно остановиться. У запроса всегда есть тело, а также может быть спецификатор и хвост
Тело — это общий термин или понятие (смартфон, велосипед, квартира). Спецификатор определяет потребность (купить, заказать, как выбрать), а хвост передаёт детали (в Москве, недорого, скидки).
Если упростить, то получается у запроса «купить телефон недорого» слово «телефон» является телом запроса, «купить» спецификатором, а «недорого» — хвостом.
N.B. 4 и 5 фактор зависят друг от друга, так как частотность тесно связана с длиной запроса и его конверсией. Получается, что общий запрос, состоящий только из тела, будет частотным, но менее конверсионным, чем хвостовой запрос. Из этого следует, что хвостовые запросы в среднем более конверсионные. Повышенная конверсионность связана с уже сформированной потребностью человека и пониманием, как удовлетворить свои желания.
Пример: «купить айфон» и «купить iphone xr 128 gb». Первый запрос хоть и указывает на потребность в покупке, но и показывает общую неопределённость пользователя. А если человек ищет запрос наподобие второго, от покупки его отделяет всего один шаг.
Шестой фактор — сезонность поискового спроса. Автором статьи замечено, что спрос на новогодние туры начинается уже в сентябре, а отдых на майские праздники бронируют в феврале. Если вы точно знаете про сезонность в своём бизнесе, то будьте уверены, что она будет проявляться и в частотности запросов.
Возникает важный вопрос: классификация интересная, но что мне с ней делать? Об этом подробнее поговорим ниже.
Программы для сбора СЯ
Есть много инструментов, платных и бесплатных, которые помогают как собрать, так и кластеризовать. Рассмотрим, как создать семантическое ядро с помощью них.
Key Collector
Он подойдет профессионалам, потому что платный. Сервис собирает СЯ, парсит подсказки, удаляет ненужные с помощью стоп-слов, фильтрует и ищет неявные дубли. Это многофункциональный инструмент, который экономит время.
SlovoEB
Бесплатная программа, которая является аналогией предыдущей. Часть задач она может выполнять самостоятельно, часть — нет. Для использования нужно вводить почту Яндекса, однако сам поисковик может заблокировать за большое число обращений.
Yandex Wordstat
Бесплатный сервис, который показывает статистику словосочетаний за месяц, данные в регионе, динамику и сезонность. С помощью него можно подобрать основные ключи для построения СЯ.
Google Keyword Planner
Он подходит для поиска с учетом пользователей Гугла. Он ищет новые запросы, создает статистику, прогнозирует трафик и предлагает новые комбинации.
Serpstat
Небесплатный сервис, которые анализирует ваши ключевые фразы и подбирает СЧ, НЧ. В нем можно задать географию, получая информацию с Яндекса и Гугла.
Mutagen
Хороший инструмент, который определяет конкуренцию запроса. Однако как именно он это делает — неизвестно, потому что разработчики не раскрывают эту информацию, и проверить это нельзя.
Keyword Tool
Альтернативный инструмент Планировщику от Гугла, разработчики презентуют его лучшую альтернативу. Часть версий бесплатны, а за профессиональный функционал придется доплатить.
Он ищет ключи в Гугле, Амазоне, Ютубе и других англоязычных сервисах, поэтому его часто используют для сбора иностранной семантики.
Just Magic
Недорогое дополнение, которое помогает работать с СЯ. В нем есть расширения для парсинга, а также Акварель Генератор — уникальная разработка, которая собирает LSI-ключевики. Это помогает увеличить релевантность текста.
Pixel Tools
Крупный дорогой инструмент. В нем множество дополнений, которые помогают SEO-специалисту, однако часть из них доступны безвозмездно. Показывает данные по геозависимости, коммерциализации и локализации.
Ahrefs
Платное дополнение, которое помогает с анализом обратных ссылок. Можно посмотреть примерное СЯ конкурентов, трафик и относительные запросы пользователей.
С помощью всех рекомендаций и программ вы только на практике поймете, как собрать семантику и ключевые слова для сайта.
Зачистка списка
Теперь нам необходимо сделать зачистку ключевых слов в списке масок. Для этого необходимо отсортировать наш список в порядке убывания параметра «частотность» (количество обращений в поисковую систему пользователей сети Интернет по ключевому запросу, т.е. это мера его популярности).
Сортирование запросов по частоте
Для чего это нужно? Каждый ключевой запрос будущего семантического ядра сайта – это потенциальный трафик из сети Интернет. И чем больше посещений будет на целевую страницу с этим словом, тем больше показов и соответственно больше вероятность совершения транзакции (совершение какого-либо действия на странице сайта – например, в нашем случае “покупка компьютера”).
Поэтому, зная предполагаемое количество посещений, можно планировать количество потенциальных посетителей (в нашем случае для компьютерного магазина, потенциальных покупателей).
Для сортировки по частотности можно использовать различные ресурсы, начиная от специализированных программ (например, платная программа “KeyCollector” или бесплатная” СловоЁб”) и заканчивая различными сервисами систем автоматического продвижения (SeoPult, WebEffector, Rookee)и сервисами поисковых систем (Wordstat Яндекс и Google AdWords – Keyword Tool). Для сортировки ключевых слов часто используют последние два сервиса, как первоисточник статистики посещений. Для нашего примера воспользуемся сервисом Яндекса. Отличный сервис для создания семантического ядра.
Сервис Wordstat.yandex.ru
Если Вы еще не знаете, как использовать в своей работе Вордстат, предлагаю следующий материал:
Для получения частот ключевых слов списка масок необходимо совершить следующие действия:
а) переходим в статистику ключевых слов и пишем первую фразу из списка масок. Если продвижение сайта будет происходить в определенном регионе, необходимо “уточнить регион”. После ввода ключевого запроса появятся две колонки с запросами. В левой колонке показан список словосочетаний, включающий нашу фразу и число показов в месяц. В правой колонке можно увидеть похожие ассоциативные запросы со своими частотами, которыми можно пополнить список масок будущего ядра (рисунок 8). Записываем каждое ключевое слово или словосочетание;

Рисунок 8. Проверка частотности ключевиков ядра
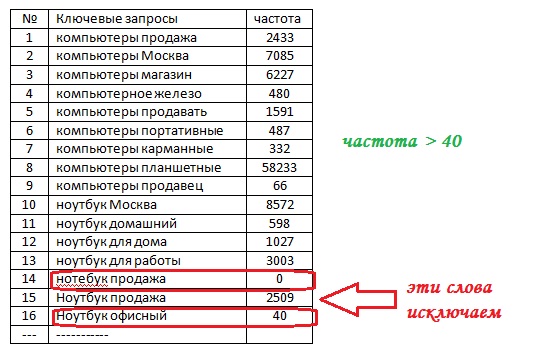
Рисунок 9. Корректировка списка с учетом заданной частотности
в) теперь посмотрим частоту точного вхождения ключевой фразы. Это делается следующим образом: ключевой запрос, у которого мы хотим узнать количество показов, заключаем в кавычки и ставим перед ними восклицательный знак (рисунок 10);
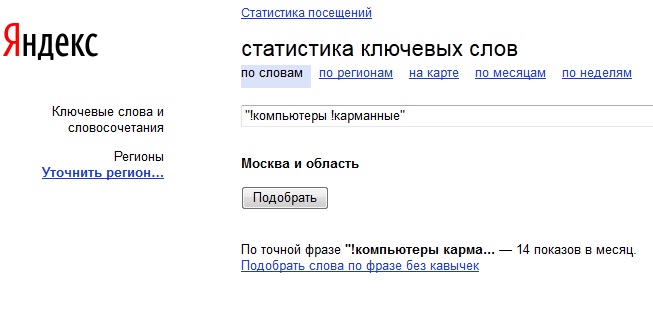
Рисунок 10. Проверка частотности точных вхождений ключевых фраз
г) после просмотра всех ключевых фраз из нашей измененной таблицы исключаем слова, у которых точная частота меньше 10 (рисунок 11). Такие словосочетания называются словами-пустышками. Из-за мизерного количества показов они не принесут трафик на целевые страницы. В итоге получается таблица-прогноз посещаемости сайта в течение месяца.
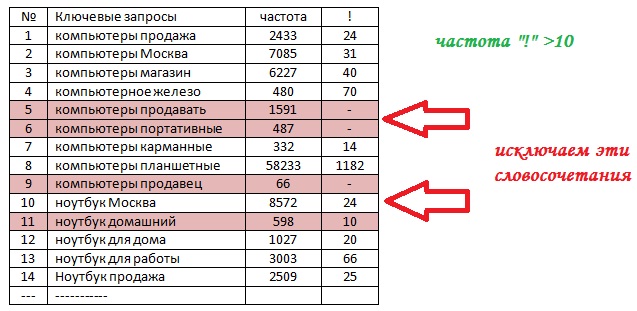
Рисунок 11. Конечная корректировка списка ключевых запросов
Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:

После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
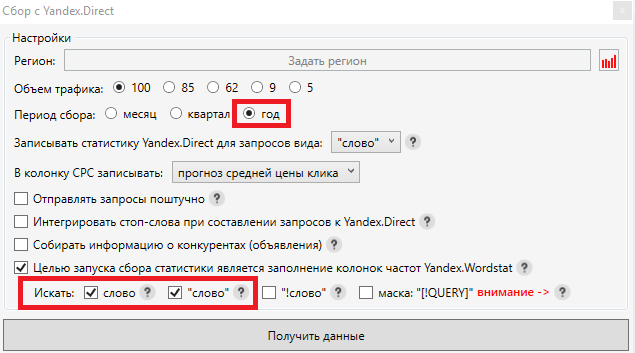
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:

Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.

Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Кластеризация запросов
После сбора и чистки семантики необходимо распределить ключевые запросы по страницам. Для этого нужно собрать ТОП выдачи по каждой фразе, после чего найти одинаковые URL. Какой порог кластеризации вы зададите – столько повторяющихся URL должно быть, чтобы ключевые фразы попали в одну группу.
Кластеризация может быть выполнена по трем методам:
- Soft – самый мягкий, используется при низкой конкуренции в тематике. В нем достаточно, чтобы запрос имел общие URL хотя бы с одним ключом из своей группы.
- Middle – более строгий метод, подходит для информационных ресурсов или для коммерческих с невысоким уровнем конкуренции. В нем определяется основной запрос группы, с которым должны быть совпадения по URL у всех остальных.
- Hard – самый строгий метод, используется для коммерческих ресурсов в тематиках с высокой конкуренцией. Все фразы в группе должны иметь друг с другом пересекающиеся URL.
Сервисы, которые помогут кластеризовать поисковые фразы
KeyAssort создан именно для кластеризации запросов. Использует все три метода кластеризации, о которых мы рассказали выше. Инструмент платный, есть демоверсия.
Группировка от Кулакова бесплатный онлайн-кластеризатор. Требует ручной коррекции результата. За один раз можно кластеризовать до 1000 фраз.
Топвизор разработал свой инструмент для группировки. Метод кластеризации можно выбрать самостоятельно. Инструмент платный, есть пробный период.
Rush Analytics также создал свой инструмент для кластеризации семантического ядра. Использует методы Hard и Soft. Тарифные планы начинаются от 500 руб.
Overlid инструмент для полноценной работы с семантическим ядром. Проводит кластеризацию на основе более чем 20 факторов. Обработка одной поисковой фразы стоит от 19 коп.
Pixel Tools предлагает четыре метода кластеризации. Три из них стандартные, а четвертый уникальный метод компании. Функция кластеризации доступна на платном аккаунте, стоимость тарифа от 950 руб. в месяц.
Arsenkin предлагает два метода кластеризации: Soft и Hard. Глубину проверки можно увеличить до ТОП-30. Инструмент доступен на платном аккаунте, стоимость тарифа от 549 руб. в месяц.
JustMagic использует только метод Hard-кластеризации. Есть бесплатная часть, но, чтобы получить полный функционал, необходимо купить подписку от 999 руб. в месяц.
После автоматической кластеризации семантического ядра обязательно вручную проверьте полученную структуру и ключевые запросы. Одиночные фразы, которые не вошли ни в одну группу, имеет смысл отложить или расширить, чтобы на страницу вело несколько ключевых слов.
4) Как составить семантическое ядро: группируем запросы
Дабы понимать, каким образом проводить распределение слов по конкретным страницам, следует выполнить группировку всех отобранных вами запросов. Для этого следует сформировать так называемые семантические кластеры.
Под данным понятием подразумевается группа схожих по тематике, смыслу «ключей», которая оформляется в виде многоуровневой структуры. Допустим, кластер первого уровня – это поисковый запрос «постельное белье». А вот кластерами второго уровня будут поисковые запросы «одеяла», «пледы» и тому подобное.
В большинстве случаев определение кластеров осуществляется при мозговом штурме
Но важно отлично разбираться в ассортименте, особенностях своего товара, но также учитывать и то, каким образом построена структура конкурентов
Следующее, на что нужно обязательно обратить особое внимание – на последнем уровнем кластера должны быть только те запросы, которые точно соответствуют единственной потребности потенциальных клиентов. То есть, конкретному виду товаров
Тут вам на помощь снова придет все тот же сервис Словоеб и описанная выше опция Быстрого фильтра. Он поможет выполнить сортировку поисковых запросов по определенным категориям.
Чтобы выполнить такую сортировку вам нужно выполнить несколько простых шагов. Сначала в поисковой строке сервиса вводите ключевое слово, которое будет использоваться при наименовании:
- категории;
- посадочной страницы и т.д.
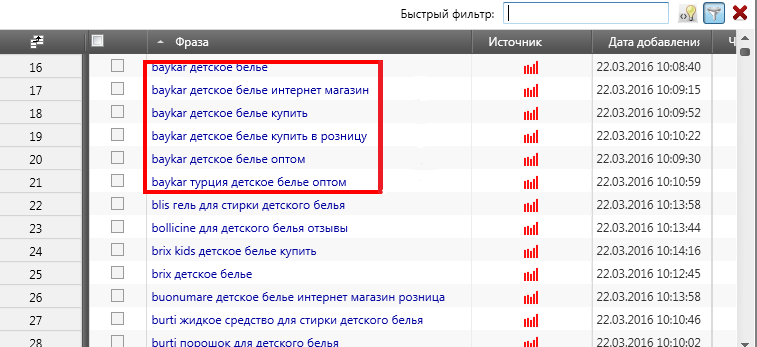
Например, это может быть бренд постельного белья. В полученных результатах пометьте фразы, которые подходят вам и скопируйте.
Те фразы, что вам не нужны, просто выделите правой кнопкой мыши и удалите. 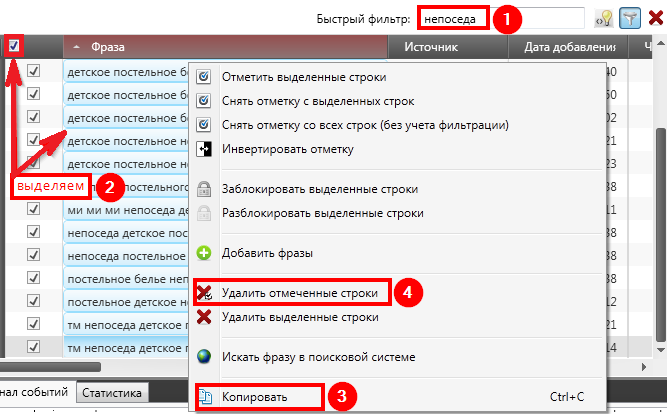
В правой части меню сервиса сделайте новую группу, назвав ее соответствующим образом. Например, наименованием бренда.
Чтобы перенести выбранные вами фразы в эту часть вкладки, необходимо выбрать строку Данные и кликнуть по надписи Добавить фразы. Подробнее – смотрите скрин.

Нажав Enter в графе поиска, вы возвратитесь к изначальному списку слов. Проделайте описанную процедуру со всеми остальными запросами.
Все отобранные фразы система будет выдавать в алфавитной последовательности, что упрощает работу с ними – вы легко сможете определить, что именно можно удалить. Или же сгруппировать слова в определенную группу.
Добавим, что ручная группировка также требует достаточное количество времени. Особенно, если речь идет о слишком большом количестве ключевых фраз. Поэтому рекомендуем воспользоваться автоматизированными платными программами. К таковым относятся:
- Key Collector;
- Rush-Analytics;
- Just-Magic и другие.
Также имеется полностью бесплатный скрипт Devaka.ru
Кстати, обратите внимание, что часто приходится объединять некоторые типы запросов. . Поскольку нет никакого смысла нагромождать на сайте огромное число категорий, отличающихся только такими названиями, как «Красивое постельное белье» и «Модное постельное белье»
Поскольку нет никакого смысла нагромождать на сайте огромное число категорий, отличающихся только такими названиями, как «Красивое постельное белье» и «Модное постельное белье».
Чтобы определиться с важностью каждой отдельной ключевой фразы для той или иной категории, достаточно просто перенести их в планировщик Google, как показано на скрине
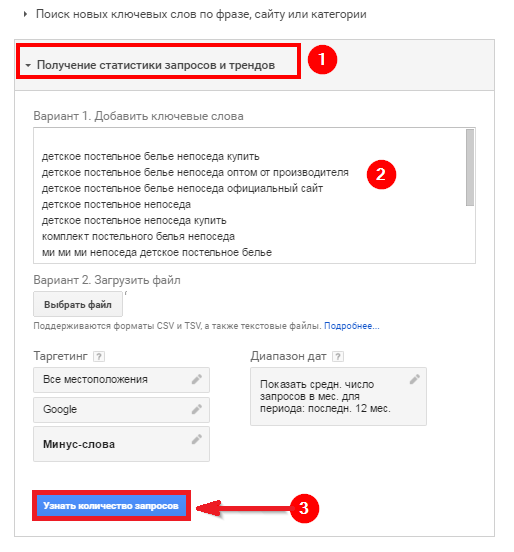
Таким образом, вы сможете определить, насколько востребован тот или иной поисковый запрос. Все их можно разделить на три категории, в зависимости от частности использования:
- высокочастотные;
- низкочастотные;
- среднечастотные;
- и даже микро-низкочастотные.
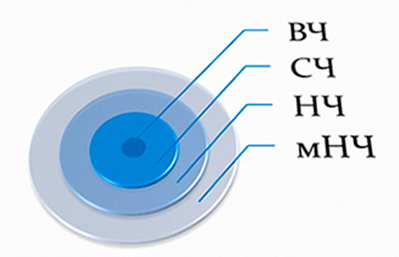
Однако важно понимать, что точных цифр, которые отображают принадлежность запроса к определенной группе, нет. Здесь следует ориентироваться на тематику, как самого сайта, так и запроса
В отдельном случае запрос с частотой до 800 в месяц может считаться низкочастотным. В другой же ситуации запрос с частотой до 150 будет являться высокочастотным.
Самые высокочастотные запросы из всех отобранных впоследствии будут вписаны в теги. А вот самые низкочастотные рекомендовано использовать для того, чтобы оптимизировать под них конкретные страницы магазина. Поскольку среди таких запросов будет низкая конкуренция, хватит просто наполнить такие подразделы качественными текстовыми описаниями, дабы страницы оказалась в первых рядах поисковой выдачи.
Все перечисленные выше действия позволят вам сформировать четкую структуру, в которой будут иметься:
- все необходимые и важные категории – чтобы сделать визуализацию «скелета» вашего магазина, воспользуйтесь дополнительным сервисом XMind;
- посадочные страницы;
- страницы, в которых представлена важная для пользователя информация – например, с контактными данными, с описанием условий доставки и т.д.
Автоматический сбор семантического ядра онлайн
А теперь поговорим о самых востребованных сервисах по сбору семантического ядра.
Wordstat
Эту программу можно считать первоисточником, поскольку другие инструменты так или иначе взаимодействуют с данными поисковой системы. В первую очередь выберите несколько запросов, максимально точно отражающих суть вашего бизнеса. Допустим, вы продаете цифровые фотоаппараты. Представьте, что лично ищете любой аналогичный магазин в Интернете. В качестве примера приведем запрос «купить фотоаппарат».
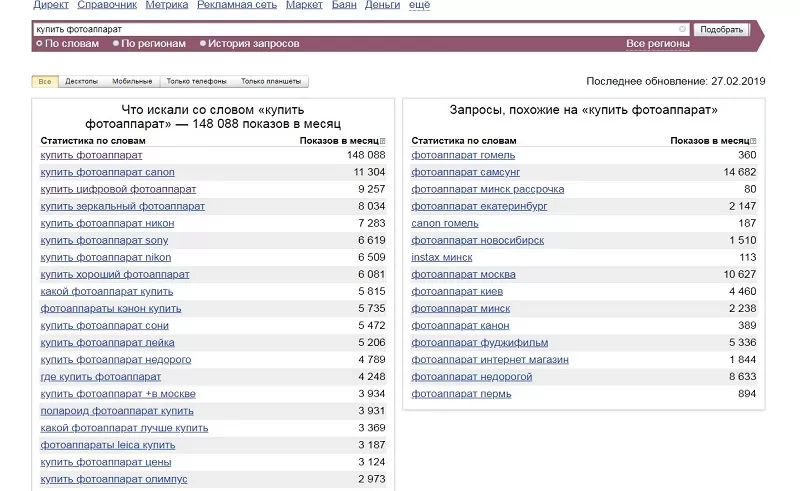
Слева в колонке – фразы, которые аудитория искала вместе с фразой «купить фотоаппарат». Не забывайте, что из перечня полученных фраз надо отсеять все лишние запросы. Вы ведь не продаете фотоаппараты на Avito?
Если вы не уверены, к какой категории относится запрос (коммерческий он или нет), просто впишите его в строку поиска и проанализируйте результаты выдачи. Если в ней больше блогов и журналов, то запрос, по всей вероятности, информационный. Например, в ключи может попасть фраза «какой фотоаппарат купить в 2019 году».
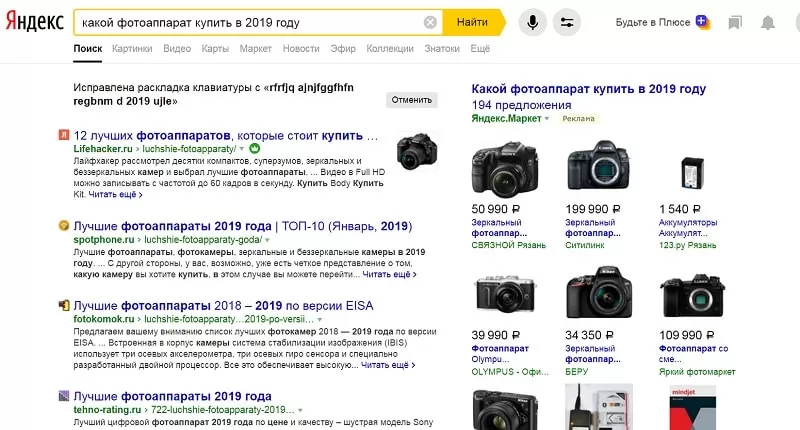
По запросу «какой цифровой фотоаппарат купить в 2019 году» поисковая система выдает только инфосайты.
Давайте подробнее поговорим о Wordstat как о программе для сбора семантического ядра. В колонке справа указаны фразы, схожие с начальным запросом. Но лишнего здесь, конечно, больше. Ваша задача – пользоваться только теми фразами, которые реально отражают специфику бизнеса, и, безусловно, исключать инфозапросы типа «качественный фотоаппарат». Правой колонкой можете пользоваться, чтобы искать синонимы. К примеру, мало кто может с первого раза правильно написать название японской марки fujifilm. Встречаются запросы «фиджифильм», «фудзифилм» и т. п. Все эти вариации также нужно включить в состав семантического ядра.
Анализируя запросы, вы обязательно увидите, что пользователи ищут фототехнику по ряду определенных критериев:
- стоимость (купить недорого);
- марка (купить фотоаппарат самсунг, кэнон, сони);
- модель (купить фотоаппарат canon powershot);
- характеристики (купить цифровой фотоаппарат, купить зеркальный фотоаппарат);
- регион (купить фотоаппарат в казани, купить фотоаппарат в краснодаре).
Эти данные позволяют вам сформировать так называемые маски запросов, в частности:
- фотоаппарат + действие (купить, заказать, с доставкой по РФ);
- фотоаппарат + стоимость (недорого, дешево, по акции, до 10 тыс., до 50 тыс.);
- фотоаппарат + марка;
- фотоаппарат + марка + модель;
- фотоаппарат + характеристика (64 гб, с nfc, 12 дюймов, с двумя симками);
- фотоаппарат + еще какой-то запрос (легкий, в качестве подарка).
Определив маски запросов, вы:
- Грамотно распределите посадочные страницы на сайте по категориям и характеристикам товаров.
- Разработаете страницы под популярные поисковые запросы (например, недорогой фотоаппарат).
- Растиражируете выбранные маски запросов на все остальные группы товаров.
- Сделаете шаблон для сбора семантического ядра.
На этой ступени мы не советуем сильно акцентировать внимание на частотности запроса. В список можете включать любые непустые фразы (с частотой от 1), связанные с вашим бизнес-проектом
При помощи каких фраз вы продвигаете и рекламируете свой товар, дело второе. На данном этапе главная задача – сбор полноценного семантического ядра.
RushAnalytics
Программа Rush Analytics помогает сделать сбор запросов из левой колонки Wordstat более автоматизированным с последующей загрузкой данных в таблицу Excel.
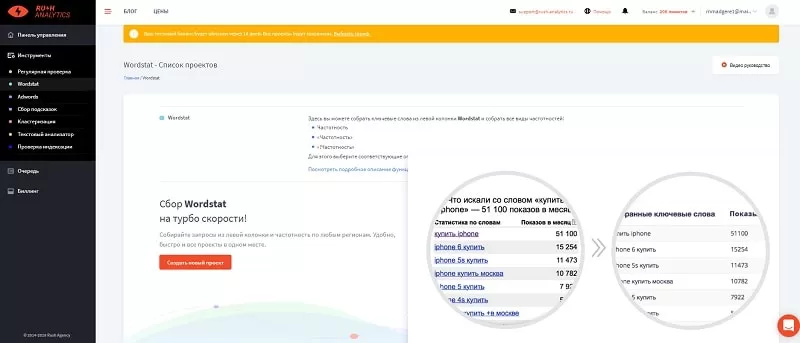
В нашем примере нужно лишь запустить сбор ключей по запросам «фотоаппарат». Но есть одна важная деталь. Wordstat по умолчанию отдает всего 41 страницу с результатами. Как вы понимаете, все запросы по такой схеме получить не удастся. Для обхода ограничения необходимо воспользоваться методом сбора частотности для запросов заданной длины (до 7 слов).
Для этого следует добавить запросы в Wordstat таким образом (обязательно нужны кавычки):
- «фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат, фотоаппарат»;
- и так далее – до 7 слов.
Этот метод поможет в сборе максимального количества запросов по вашей теме.
Spywords.ru
Программа spywords.ru дает возможность несколько облегчить себе задачу и собрать семантическое ядро не с нуля, а с помощью сайтов-конкурентов.

Принцип работы предельно прост: нужно выбрать 3–4 лидера в вашей отрасли и собрать все фразы, по которым их ранжируют поисковики в пределах Топ-100.
Конечно, так вы, скорее всего, не соберете полноценную семантику. Но с большой долей вероятности охватите процентов 60, и для начала этого достаточно.
Что такое семантическое ядро сайта
Начнем с определения:
Обратите внимание, что есть прямая взаимосвязь между ключами и страницами сайта: каждому слову/фразе должна быть сопоставлена одна конкретная страница (URL). Само собой, один URL может быть связан с несколькими ключами
Какое количество ключевых слов должно быть для одной страницы? Есть общая рекомендация, чтобы одной странице соответствовало не более 10 ключей. Но такой подход не всегда работает. Если у вас есть 20 или 30 ключей, которые по смыслу подходят строго к одной странице и разделение их на две страницы будет нелогичным, то не нужно «переоптимизировать» сайт и создавать две страницы с фактически одинаковым содержанием под похожие ключи.
Разрабатывая семантическое ядро и впоследствии структуру сайта, помните о следующих моментах:
- страница должна соответствовать ожиданиям посетителя;
- страница сайта = решение проблемы человека;
- сайт должен давать ответы на максимальное количество запросов по тематике;
- полная семантика сайта = структура сайта.

Услуги по сбору семантического ядра
В данной отрасли можно найти не мало организаций, которые готовы предложить вам услуги по кластеризации. Например, если вы не готовы тратить время на то, чтобы самостоятельно изучить тонкости кластеризации и выполнить ее собственными руками, то можно найти множество специалистов, готовых выполнить эту работу.
Yadrex
Yadrex — одна из первых на рынке, кто начал использовать искусственный интеллект для создания сематического ядра. Руководитель компании сам профессиональный вебмастер и специалист по SEO технологиям, поэтому он гарантирует качество работы своих сотрудников.
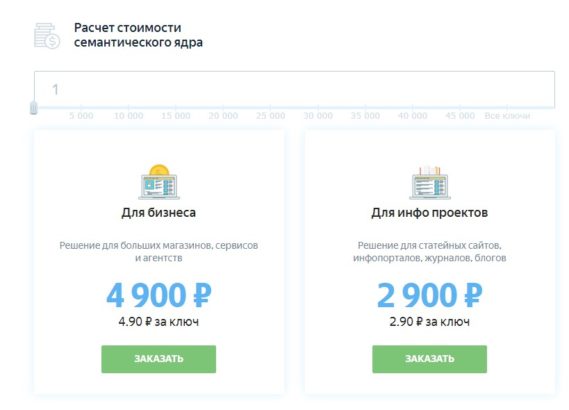
На сайте, вы можете самостоятельно рассчитать стоимость создания сематического ядра для вашей задачи.
Кроме того, вы можете позвонить по указанным телефонам, чтобы получить ответы на все интересующие вас вопросы относительно работы.
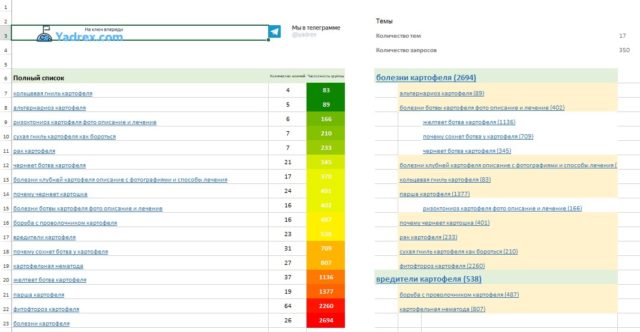
Заказывая услуги, вы получите файл, где будут указаны группы содержания ядра и его структура. Дополнительно вы получаете структуру в mindmup.
Стоимость работы варьируется в зависимости от объема, чем больше объем работы, тем дешевле стоимость одного ключа. Максимальная стоимость для информационного проекта будет 2,9 рублей за один ключ. Для продающего 4,9 рублей за ключ. При большом заказе предоставляются скидки и бонусы.
Бесплатный парсинг запросов конкурентов
Чтобы парсить конкурентов, их надо знать. В анализе ниш я уже рассказывал, как определить своих конкурентов.
Выписываем всех ваших конкурентов, если вы еще этого не сделали. Надо брать только прям точных конкурентов. Например, у вас сайт по диабету, вам надо брать только сайты по диабету. Сайты, которые посвящены всей медицине с разделом диабета не подойдут, потому что у вас напарсятся другие разделы сайта, которые посвящены не диабету, и вы запаритесь их чистить.
Wizard.Sape
Заходите в KeyCollector во вкладку Wizard.Sape. Выбираем анализ доменов. Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.
Вводим логин, пароль. Любой тематический url и своих конкурентов списком. Нажимаем начать сбор.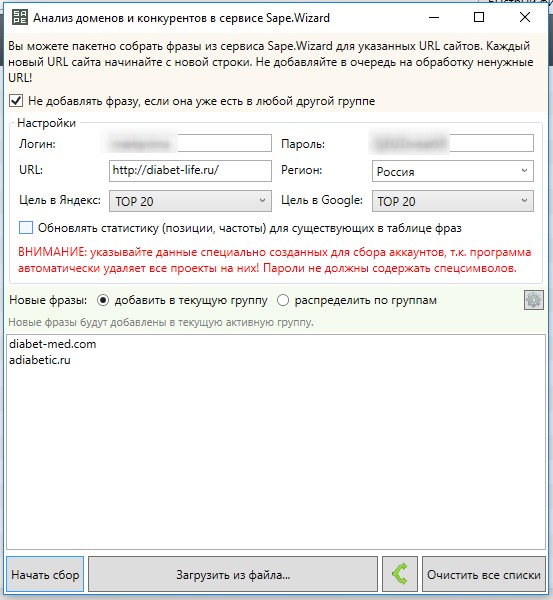 После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
После сбора, в колонке частотность wordstat, появляются цифры сервиса их необходимо очистить.
Так же можно еще собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Megaindex
Заходим в KeyCollector во вкладку Megaindex. Вводим логин и пароль, указываем Москва, потому что Россию нельзя указать. Выбираем последнюю дату, раньше можно было парсить за весь период, но сейчас почему-то не работает, можно выбирать только определенную дату. Вбиваем домены конкурентов. И начинаем парсинг.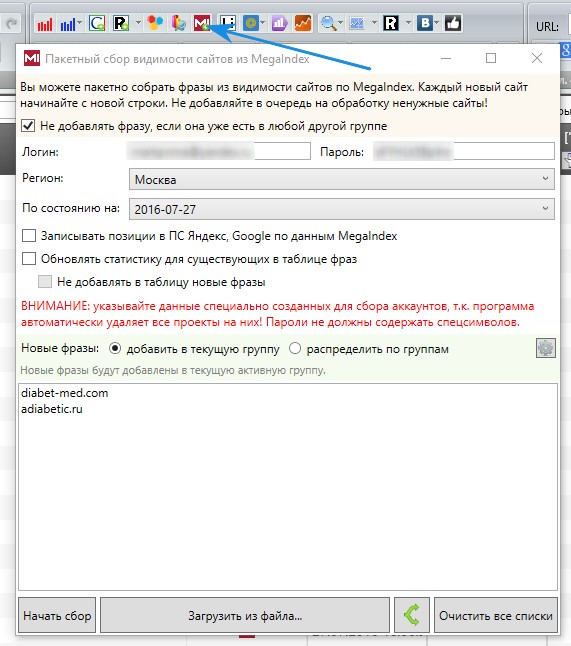
Rookee
Выбираем Rookee в Keycollector, составление семантического ядра.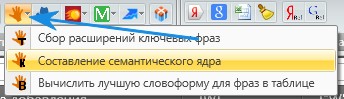 Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Здесь все проще, выбираем Москва, топ 10 и вводим конкурентов с http://
Можно отдельно собрать по Яндексу, потом по Гуглу.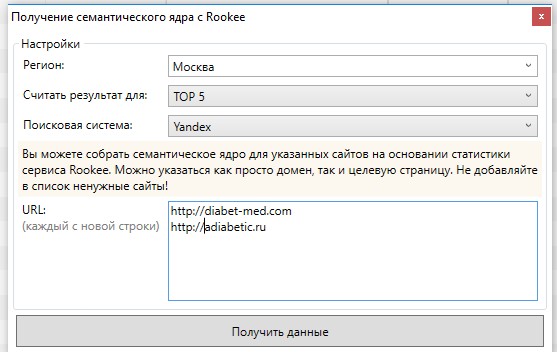 Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Так же можно собрать “сбор расширений ключевых фраз” в той же самой вкладке в KeyCollector.
Top.Mail.ru
Здесь все сложнее. Необходимо перейти в рейтинг https://top.mail.ru/, и там найти ваших конкурентов с открытым счетчиком. Обычно что-то узконишевое там сложно найти, но все равно расскажу про этот способ для общего кругозора.
Вводим вашу тематику в поле поиска рейтинга.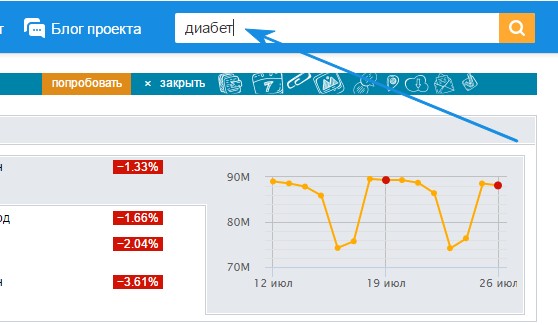 Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта.
Получаем сайты. Как видим нашей тематики тут нет. Замочек напротив сайта – стата закрыта. Значок рейтинга – стата открыта. Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id.
Так вот, если бы мы делали сайт не по диабету, а по косметике, то первый сайт бы нам подошел. У него открыта стата и мы можем спарсить её. Переходим на него и смотрим его id. В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.
В KeyCollector щелкаем на значок mail, сбор статистики из счетчиков TOP.MailУказываем id счетчика и выставляем самый большой срок данных, 3 года.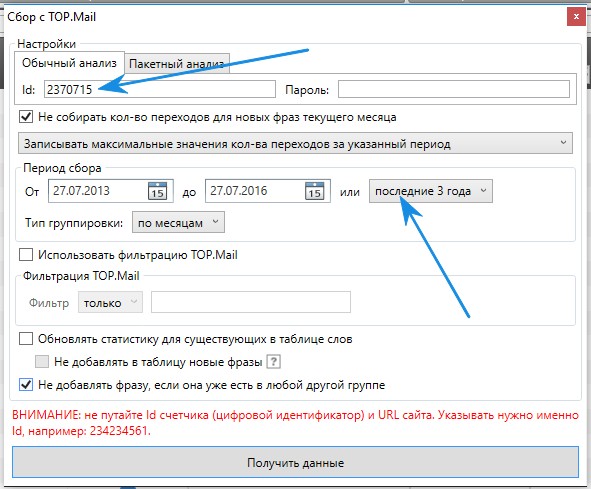 Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Есть так же пакетный анализ, где можно указывать сразу много счетчиков.
Так же можно спарсить глобальный рейтинг top.mail по ключевым словам, в той же самой вкладке в KeyCollector.
На этом бесплатный сбор ключевых слов у конкурентов закончен. Теперь его надо очистить и оставить только нужное.
В итоге получаем готовый список ключевых слов конкурентов, которыми можем дополнить наше ядро.