Помощники по сбору семантического ядра
Содержание:
Шаг 1. Определить темы для статей
Начинаем всегда работу с анализа конкурентов. Смотрим:
- какие разделы есть у сайтов конкурентов;
- на какие темы можно писать тексты в вашей тематике.
Нам нужно определить точки входа на сайте — разделы блога. Например, есть блог про чай. В нем могут быть разделы: зеленый чай, черный чай, кофе. Писать статьи нужно последовательно. Пока не заполнили текущий раздел — не охватили все возможные тематики — не переходите к следующему.
Статья не попадет в топ выдачи, если не охватить тему целиком.
Примеры определения разделов в тематиках:
- Если продаем товары: пишите о конкретных товарах и их преимуществах, сравнение (что лучше выбрать), подборки, инструкции.
- Если оказываем услуги: пишем о проблемах, которые решает конкретная услуга, как сделать что-либо своими руками, как научиться делать самостоятельно, как исправить ошибки и так далее.
При определении разделов в вашей тематике просто посмотрите на конкурентов в ТОПе.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:

Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Наши клиенты
Комплексная поддержка сайта концерна
Компания «HEINEKEN Russia»
Концерн HEINEKEN один из мировых лидеров пивной отрасли.
Поддержка сайтов группы компаний Bridgestone СНГ
Компания «Bridgestone»
Японская корпорация с штаб квартирой в Токио, возглавляет ТОП-10 мировых компаний-производителей шин.
Оптимизация сайта, контекстная реклама
Компания «Samsonite»
Крупнейший американский производитель чемоданов и ручной клади. Базируется в США, штат Колорадо.
Проектирование, продвижение и разработка сайта
Компания «Окна Роста»
Один из лидеров компаний-производителей пластиковых окон и дверей в России.
SEO, разработка сервиса внутреннего обучения
Компания «Аскона»
Крупнейший в России производитель ортопедических матрасов и товаров для сна.
Комплексное SEO банковских продуктов и услуг
Банк «Промсвязьбанк»
Входит в ТОП-3 частных банков России и в 500 крупнейших банков мира.
Ведение рекламных кампаний, поддержка и создание сайта
Компания «Goodyear»
Американская компания, одна из крупнейших в мире производителей автомобильных шин.
Поддержка сайта компании Garmin в России
Компания «Garmin»
Крупнейший мировой производитель GPS-навигационной техники с штаб-квартирой в США.
Создание сайта для внутреннего использования
Банк «Совкомбанк»
Совкомбанк основан в 1990 году, входит в 20-ку крупнейших банков по активам в России по состоянию на 2016 года.
Поддержка сайта страховой группы
Страховая группа «СОГАЗ»
Страховая группа «СОГАЗ» — одна из крупнейших российских страховых компаний, отнесена к разряду системообразующих.
Поддержка сайтов производителя смесей
Строительные смеси «ОСНОВИТ»
Одна из лидирующий торговых марок строительных смесей в России.
Комплексное SEO для ведущего E-Commerce проекта России
Компания «Юлмарт»
Юлмарт занимает третью строчку среди самых крупных интернет-компаний России по версии Forbes.
Создание, поддержка и комплексное продвижение
Компания «Линзмастер»
Крупнейшая в России сеть салонов оптики. Более 85 салонов в 12 крупнейших городах по всей стране.
Поддержка сайта и внедрение аудитов
Банк «Bank of China»
Второй по величине и самый старейший банк КНР, зарубежная филиальная сеть насчитывает свыше 800 отделений более чем в 30 странах.
Создание корпоративного сайта корпорации
Компания «RISO»
Японская корпорация RISO занимает ведущее место среди изготовителей цифровых множительных аппаратов.
Подготовка ТЗ и прототипов для MAPS.ME
Компания «Mail.Ru Group»
Крупнейшая технологическая компания России, входит в ТОП-2000 крупнейших мировых компаний по версии Forbes.
Комплексное продвижение сайта
Компания «SsangYong»
Разработка и поддержка сайта
Компания «Газпром теплоэнерго»
Специализированный теплоэнергетический холдинг, работающий в области энергетики.
Виды поисковых запросов
Все поисковые запросы можно разделить на виды, в том числе по объему их показов в поиске.
Информационные
По этим запросам люди ищут информацию о вещах и явлениях, отзывы о товарах, обзоры и прочее.
Примеры информационных запросов: «первые признаки беременности», «рецепт борща», «чем отстирать пятно» и т. д.
Такие запросы в первую очередь подходят для информационных (контентных) сайтов, которые как раз и отвечают на вопросы пользователей.
Информационные запросы можно использовать и для продвижения коммерческих проектов:
- они привлекают дополнительный трафик в корпоративные блоги;
- приводят пользователя в каталоги, по ссылкам из которых он будет переходить на разделы с товарами;
- помогают расширить объем релевантного контента;
- используются для рекламы продаваемых товаров или услуг в блоге.
Как правило, частотность (количество показов) информационных запросов может быть существенно выше, чем коммерческих. Это позволяет получать большой объем трафика на сайт. Однако такой трафик будет низко конвертируемым для коммерческих проектов.
Коммерческие запросы (транзакционные)
Эти запросы пользователи используют, когда хотят купить товар или получить услугу.
Например: «купить пылесос», «гастроэнтеролог запись на прием», «доставка пиццы».
Обычно в коммерческих запросах есть слова, которые так или иначе связаны с процессом покупки:
Витальные (навигационные, брендовые)
Витальные запросы пользователь вводит, когда его интересует сайт конкретной компании, бренда или проекта: «тинькофф», «авиасейлс», «сайт госуслуг».
Страницы этого сайта будут занимать первые строки выдачи.
Однако специально использовать навигационные запросы в продвижении не стоит, они и так окажутся в топе по соответствующим запросам.
Общие запросы
Общие, или неточные запросы, как правило, самые высокочастотные, но использовать их для поискового продвижения бессмысленно.
Мультимедийные (фото, видео, музыка)
Как и следует из названия, такие запросы пользователи вводят, когда ищут медийный контент. Причем он может быть из самых разных областей, например, человек хочет скоротать вечер («смотреть онлайн дом 2») или готовится к ремонту («ручная дрель фото»).
В таких фразах часто есть слова «фото», «аудио», «видео», «смотреть», «слушать», «скачать».
Геозависимые (ГЗ) и геонезависимые (ГНЗ) + город
Выдача по ГЗ запросам в разных регионах будет отличаться. При этом в них не содержится указание на географическую точку. Например, если вы, будучи в Новосибирске, наберете в поисковике фразу «заказать такси» или «записаться к зубному», то увидите местные сайты. А человек в Москве по такому же запросу – столичные.
ГЗ по большей части относятся к коммерческим запросам.
Геонезависимые запросы, напротив, не привязаны к географии и покажут одну и ту же выдачу, где бы не находился пользователь. Это может быть фраза «выращивание кактусов» или «космические полеты».
Любопытно, что ГНЗ включает и запросы, в которых есть прямое указание на регион. Например, по запросу «доставка цветов рязань» пользователь увидит практически идентичную выдачу, где бы он ни находился (и в Рязани, и нет).
Запросы по частоте показов
Частота, или частотность запросов – это один из важнейших показателей для SEO-продвижения. Он выражается числовым значением и показывает, сколько раз фраза была показана в поисковой системе за месяц (реже за другой промежуток времени).
По этому параметру запросы делятся на следующие виды:
- Высокочастотные, ВЧ – самые «популярные» запросы у пользователей, их вводят чаще всего. Работать с ними непросто, так как именно по ВЧ самая большая конкуренция. Также нужно учитывать, что в точном виде пользователи используют их гораздо реже, чем с уточнениями.
- Среднечастотные, СЧ – промежуточные по частоте фразы между ВЧ и НЧ.
- Низкочастотные, НЧ – узконаправленные фразы, которые точнее и подробнее всего показывают потребность пользователя. Конкуренция по ним низкая, поэтому есть неплохие шансы попасть по НЧ в топ выдачи. Кроме того, продвижение по низкочастотным запросам занимает меньше времени, чем по СЧ и ВЧ.
Пример:
| Запрос | Вид | Частота | “Частота” | “!Частота” |
|---|---|---|---|---|
| беременность | ВЧ | 9782207 | 17683 | 15612 |
| признаки беременности | СЧ | 316203 | 24925 | 24032 |
| беременность первые дни после зачатия признаки ощущения | НЧ | 88 | 9 | 9 |
Видим, что СЧ запрос в точном виде спрашивают больше, чем ВЧ.
Типы запросов по смыслу
-
Общие – демонстрируют не определенную потребность пользователя, а его интересы. К примеру, «недвижимость Москва».
-
Четкие – прозрачно выражают потребность пользователя, которую он хочет удовлетворить, вводя запрос в поисковую строку браузера. Например, «куплю недвижимость в Москве». В свою очередь, четкие запросы можно разделить на следующие классы:
-
информационные – в них уточняются определенные детали. К примеру, «квартиры в Москве агентства»;
-
транзакционные – содержащие определенную отсылку к действию. К примеру, «купить квартиру в Москве»;
-
навигационные – в них пользователь указывает на виртуальные или реальные объекты. К примеру, «квартиры cian».
Если подбор семантического ядра сайта направлен на высокую конверсию трафика, то нужно стараться подбирать максимально четкие запросы. Активное использование общих запросов значительно увеличивает бюджет продвижения, параллельно уменьшая процент целевых посещений. Но если нужно добиться увеличения трафика, то навигационные и информационные общие запросы станут оптимальным решением.
Есть еще несколько рекомендаций, которые помогут эффективно провести подбор семантического ядра сайта:
Для обобщения информации рассмотрим показательный пример. Казалось бы, что плохого, если в одном запросе объединены основные услуги строительной компании?
-
Этот «длинный» запрос включает в себя несколько ВЧ-ключей, продвигать которые будет дорого и долго.
-
Сложно представить пользователя, который бы вводил в строку поиска аналогичный запрос.
-
Практически невозможно создать качественный контент, в котором бы такой запрос смотрелся органично.
В семантическом ядре не должно быть запросов с ошибками. Подобные словосочетания сразу исправляются орфографическими и синтаксическими анализаторами поисковых систем. В результате по запросу «стомОтологические клиники» будет применен редирект на страницу с результатами по «стомАтологические клиники», где продвижение не проводилось, а значит, силы и средства будут потрачены без нужного эффекта.
Также нужно учитывать тот факт, что контент, опубликованный на сайте, будет храниться годами в архивах интернета. Поэтому тексты с ошибками со временем могут быть использованы конкурентами для дискредитации вашего бизнеса.
Допущенные грамматические и морфологические ошибки в текстовом контенте могут привести к тому, что целевая аудитория просто не будет доверять бизнесу. Поисковые системы, в свою очередь, оценивают грамотность текстов на сайте, поэтому ошибки могут привести к пессимизации при ранжировании. К примеру, запросы типа «двухкомнатная квартира в москве аренда» или «купить дачу загородный дом коттедж подмосковье» просто невозможно корректно вставить в текст, поэтому лучше отказаться от их использования.
-
Избегайте неоднозначной семантики. При обработке таких запросов «Яндекс» активирует алгоритм «Спектр», который делает выдачу разнообразной по тематике. С учетом факторов персонализации можно говорить о том, что каждый пользователь получит разные результаты выдачи, что существенно сократит целевой трафик. К примеру, «ручки» могут быть дверными, пишущими, детскими или оконными. Собрать целевой трафик с такими запросами не получится.
-
Не разбавляйте семантику бессмысленными словами. Нет смысла использовать конструкции типа «купить квартиру бесплатно» или «снять квартиру бесплатно».
-
Не применяйте ВЧ-запросы общего характера. Несмотря на популярность, такая семантика не приносит целевой трафик, при этом продвижение по ней будет сложным и дорогим. Например, пользователи, которые ввели в строку поиска запрос «кредит», крайне редко готовы приступить к оформлению займа при переходе на сайт. Намного эффективнее использовать конструкции «оформить кредит» или «автокредит в москве».
-
Не используйте запросы, не соответствующие бизнесу. К примеру, запрос «купить велосипед» не принесет коммерческий эффект фирме, которая занимается велопрокатом.
Эти простые рекомендации помогут сделать подбор слов семантического ядра для продвижения сайта результативным процессом.
Плюсы и минусы анализа семантического ядра конкурентов с помощью специальных сервисов
Многие программы, определяющие ключевые слова на сторонних сайтах, работают по следующему принципу:
- Составляется перечень самых частых поисковых запросов.
- Отбирается 1−10 страниц выдачи для каждого из них.
- Сбор выдачи ключей повторяют с установленной периодичностью: неделя, месяц или год.
Подобный подход имеет свои минусы. Так, программы:
- выдают только видимую часть поисковых запросов на сайтах компаний-конкурентов;
- сохраняют у себя своего рода «шаблон» выдачи, сформированный при сборе ключей;
- способны определять видимость лишь тех поисковых запросов, которые есть в их базах;
- показывают только известные им ключи.
Кроме того:
- чтобы получить достоверные данные о ключах на сайте компании-конкурента, надо знать, когда собираются поисковые запросы (анализируется видимость);
- не все запросы отражаются в поисковой выдаче, и потому программе они не видны. Это может происходить по разным причинам: страницы сайта еще не проиндексированы, поисковая система не ранжирует их из-за длительной загрузки, содержания вирусов и т. д.;
- сведений о том, какие ключевые запросы включены в базу сервиса, используемого для сбора поисковой выдачи, как правило, нет.
То есть программа составляет не достоверное семантическое ядро, положенное в основу сайта, а только его малую видимую часть.

Основываясь на вышеизложенном, можно сказать следующее:
- Семантика конкурирующего сайта, сформированная при помощи специализированных программ, не дает полной актуальной картины.
- Чем более обширна база ключевых слов в программе, тем медленнее обрабатывается выдача и тем менее актуальна семантика. Пока программа формирует поисковую выдачу по началу базы, сведения по концу баз теряют актуальность.
- Программы не разглашают сведения о том, актуальны ли их базы и когда было последнее обновление. Поэтому вам не может быть известно, насколько ключи с конкурирующего сайта, отобранные программой, отражают его реальную семантику.
Но существенным плюсом такого подхода можно назвать получение доступа к большому количеству ключей конкурентов, многие из которых вы можете применять, чтобы расширять семантическое ядро своего сайта. Помимо этого, проверка семантики конкурирующего ресурса позволяет дополнить семантику вашей веб-площадки или проанализировать маркетинговую политику компаний-соперников.
Зачем узнавать семантику конкурентов?
Продвижение сайта – дело очень тонкое. Требует серьезного подхода и не потерпит упущений. В предыдущих статьях мы уже выяснили, что сбор семантического ядра с помощью сервисов очень важен для продвижения сайтов. Причем любого типа.

Будьте уверены, что почти все ваши соперники давным-давно промониторили ваш сайт, в том числе и по семантике. Благодаря этой информации они могут видеть, по каким именно запросам вы решили продвигаться. Само собой, такие данные помогут им сформировать собственный план продвижения и обгона вашего ресурса в позициях.
Анализ конкурентов – своего рода постулат современного бизнеса. Этому учат на различных тренингах и курсах, об этом пишут книги и статьи. Если владелец ресурса решит намеренно исключить такую практику, то в дальнейшем он рискует потерять значительную долю трафика, а равно и клиентов.
Этап 2. Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если ваш магазин находится в Москве, то и запросы с их частотностью нужно собирать по данному региону. Для этого в нижней части окна мы выбираем регион для сервисов Yandex.Wordstat и Яндекс Директ:
После выбора региона можно приступать к сбору семантики.
Методика
В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:
В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:
После нажатия на кнопку в правой колонке групп мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:
Запустив парсинг левой колонки Yandex.Wordstat, мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса Yandex.Wordstat, нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:
Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:
Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточненную» частотность, после чего нажимаем кнопку «Получить данные»:
Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточненной» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:
Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
1. Инструмент фильтрации позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
2. Инструмент «Стоп-слова» позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
3. Инструмент «Анализ групп» позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находится во вкладке «Данные»:
Во всплывающим окне можно увидеть несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице и не случится того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придется искать позже вручную в общем списке запросов.
Просматривая группы одну за другой, отмечаем их или фразы внутри них, которые явно нам не подходят. В процессе мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:
После того как отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего следует перейти к выгрузке запросов в Excel для последующей ручной чистки запросов и группировки семантики.
Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:
Пример сбора семантического ядра с помощью сервиса Wordstat Yandex
Например, вы продвигаете салон ногтевого сервиса в Москве.
Думаем и подбираем всевозможные слова, которые подходят теме сайта.
Деятельность компании
- салон маникюра;
- салон ногтевого сервиса;
- студия ногтевого сервиса;
- студия маникюра;
- студия педикюра;
- студия ногтевого дизайна.
Общее название услуг
— педикюр;
— маникюр;
— наращивание ногтей.
Теперь заходим на сервис Яндекса и вводим каждый запрос, предварительно выбрав регион, по которому собираемся продвигаться.

Копируем все слова в Excel из левой колонки, плюс вспомогательные фразы из правой.
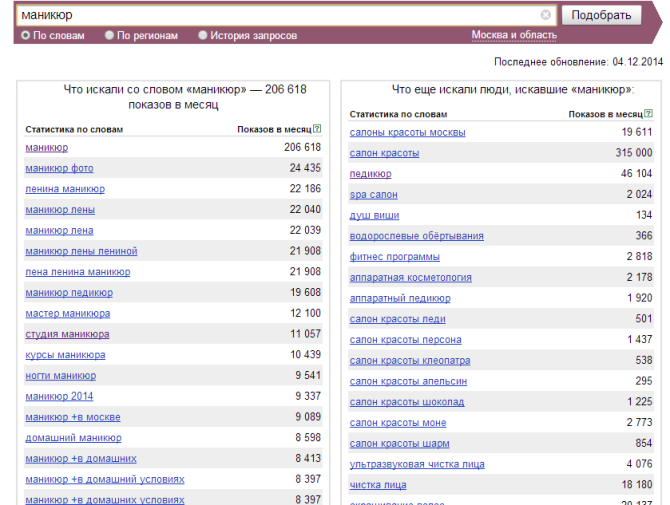
Удаляем лишние слова, которые не подходят под тематику. Ниже красным выделены слова, которые подходят.

Далее проверяем точную частотность запросов, чтобы составить правильно семантическое ядро.
Правила игры в прятки: как закрыть сайт от индексации и отображения в результатах поиска (перевод).
Цифра 2320 запросов показывает, сколько раз люди набирали этот запрос не только в чистом виде, но и в составе других словосочетаний. Например: маникюр и цена в москве, цена на маникюр и педикюр в москве и т.д.
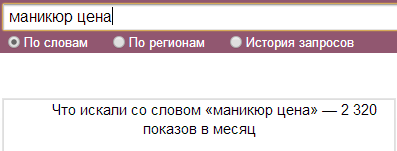
Если ввести наш запрос в кавычках, то здесь уже будет другая цифра, где учитываются словоформы ключевой фразы. например: маникюр цены, маникюр цену и т.д.
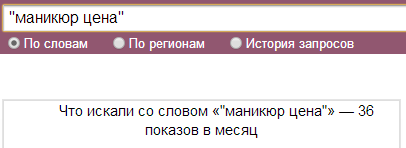
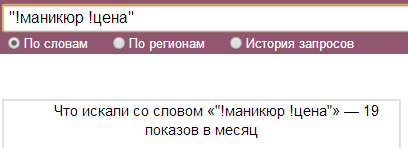
Если ввести тот же запрос запрос в кавычках с восклицательными знаками, то увидим сколько раз пользователи набирали запрос именно «маникюр цена».
Далее делаем разбивку полученного списка слов по страницам сайта. Так, например, высокочастотные запросы мы оставим на главной странице и на основных разделах сайта, такие как: маникюр, студия ногтевого сервиса, наращивание ногтей. Средне- и низкочастотные распределим по остальным страницам, например: маникюр и педикюр цены, наращивание ногтей гелем дизайн. Слова также должны быть разделены на группы по смыслу.
- Главная страница — студия, салон ногтевого сервиса и т.д.
- 3 раздела — педикюр, маникюр, цены на маникюр и педикюр.
- Страницы — наращивание ногтей, аппаратный педикюр и т.д.
С каких сайтов собирать данные?
Главный плюс анализа ключевых слов конкурентов заключается в том, что вы получите реальные запросы, по которым приходят посетители, а также сможете оценить соответствующие страницы сайта-конкурента. Однако в любом случае вам необходимо разработать свое ядро, анализ конкурентов должен лишь дополнить его, но не заменить.
В данном случае рекомендуется обращать внимание на нишевые ресурсы ограниченной тематики. Очевидно, что большие порталы типа «обо всем понемногу» вам совершенно точно не подойдут
Разве что вы сами делаете подобный проект, но там и ситуация с семантическим ядром совершенно иная.
Само собой, нужно выбирать для анализа топовые сайты, которые являются лидерами в нише. Не стоит ограничиваться одним ресурсом, это почти наверняка не даст полной картины (за редкими исключениями вроде совсем уж специфичных и узких ниш).
Программы и сервисы для парсинга
Для начала нужно подобрать около 20 базовых фраз. Для этого используем свой мозг (подумайте, какие словосочетания ассоциируются с вашим родом деятельности), поисковую выдачу по схожим запросам и данные из Яндекс.Метрики и Google Search Console (смотрим, по каким ключам больше переходов на ваш сайт).
Далее для создания хорошего семантического ядра используем специальные программы.
Бесплатные
Часть работы можно проделать, не заплатив ни копейки. Здесь на помощь приходят определенные сервисы.
Wordstat Yandex
- показывает количество и частоту запросов в Яндексе;
- фразы изменяются в падежах;
- можно задать регион;
- позволяет сделать выборку по типу устройства (ПК, планшет, смартфон);
- позволяет исключить лишние фразы.
Планировщик ключевых слов Google
- подходит для узкой тематики;
- позволяет собрать широкую базу ключей;
- показывает статистику по словам;
- прогнозирует эффективность фраз.
Букварикс
- содержит большую базу запросов;
- функции фильтрации минимальны.
При использовании бесплатных ресурсов семантическое ядро получается «грязным» — словосочетания дублируются, выдаются нерелеватные запросы, слова с нулевой частотностью, которые приходится чистить с помощью фильтров или вручную.
Платные
Для расширения ядра советуем воспользоваться платными сервисами.
Rush Analytics
- автоматизирует сбор и группировку значимых словосочетаний;
- парсит запросы через Wordstat;
- регулируемая глубина поиска;
- классифицирует запросы по типам (коммерческие и информационные).
База Пастухова
- большая база ключевых слов (на русском и английском языке);
- фильтрует запросы по числовым данным;
- есть онлайн-версия;
- из-за дороговизны больше подходит крупным компаниям.
Serpstat
- комплексный сервис для продвижения ресурса;
- выделяет запросы, по которым проект попадает в ТОП-100 выдачи;
- возможность анализировать сайты конкурентов.
Для наибольшей эффективности советуем комбинировать бесплатные и платные сервисы.
Шаг 2. Собрать информационные запросы
Начинаем со сбора информационных запросов.
Берем запросы со словами:
- как;
- какой;
- как выбрать;
- почему;
- зачем;
- и просто информационные — «Какой велосипед выбрать ребенку».
Не берем запросы с коммерческими словами:
Купить велосипед ребенку
С какими сервисами работать
Вручную через Wordstat с помощью плагина Wordstat Assistant. Регион не выбираем, потому что нам нужны только геонезависимые запросы.

Получилась семантика для статьи, например:

Так выглядит неполное и неправильное СЯ (смешали информационные и коммерческие запросы — разный интент):
Чем еще можно собирать семантику:
Keys.so — смотрим топ в выдаче по нужной теме, отправляем в сервис 2-3 адреса из топа. После парсинга получим большой список ключей, который нужно очистить от лишних запросов.
Key Collector — собирает обширное СЯ
- полное СЯ;
- собирает автоматически;
Но получится много мусора: нужно чистить, зато собирает максимально много ключей, точно ничего не пропустите.
Дорабатываем семантику в Key Collector
Когда собрали все ключи, используя key-collector:
- снимаем частотность БЕЗ указания региональности;
- убираем всё лишнее и запросы с низкой частотностью (0).

Автоматический сбор семантического ядра онлайн
А теперь поговорим о самых востребованных сервисах по сбору семантического ядра.
Wordstat
Эту программу можно считать первоисточником, поскольку другие инструменты так или иначе взаимодействуют с данными поисковой системы. В первую очередь выберите несколько запросов, максимально точно отражающих суть вашего бизнеса. Допустим, вы продаете цифровые фотоаппараты. Представьте, что лично ищете любой аналогичный магазин в Интернете. В качестве примера приведем запрос «купить фотоаппарат».
Слева в колонке – фразы, которые аудитория искала вместе с фразой «купить фотоаппарат». Не забывайте, что из перечня полученных фраз надо отсеять все лишние запросы. Вы ведь не продаете фотоаппараты на Avito?
Если вы не уверены, к какой категории относится запрос (коммерческий он или нет), просто впишите его в строку поиска и проанализируйте результаты выдачи. Если в ней больше блогов и журналов, то запрос, по всей вероятности, информационный. Например, в ключи может попасть фраза «какой фотоаппарат купить в 2019 году».
По запросу «какой цифровой фотоаппарат купить в 2019 году» поисковая система выдает только инфосайты.
Давайте подробнее поговорим о Wordstat как о программе для сбора семантического ядра. В колонке справа указаны фразы, схожие с начальным запросом. Но лишнего здесь, конечно, больше. Ваша задача – пользоваться только теми фразами, которые реально отражают специфику бизнеса, и, безусловно, исключать инфозапросы типа «качественный фотоаппарат». Правой колонкой можете пользоваться, чтобы искать синонимы. К примеру, мало кто может с первого раза правильно написать название японской марки fujifilm. Встречаются запросы «фиджифильм», «фудзифилм» и т. п. Все эти вариации также нужно включить в состав семантического ядра.
Анализируя запросы, вы обязательно увидите, что пользователи ищут фототехнику по ряду определенных критериев:
- стоимость (купить недорого);
- марка (купить фотоаппарат самсунг, кэнон, сони);
- модель (купить фотоаппарат canon powershot);
- характеристики (купить цифровой фотоаппарат, купить зеркальный фотоаппарат);
- регион (купить фотоаппарат в казани, купить фотоаппарат в краснодаре).
Эти данные позволяют вам сформировать так называемые маски запросов, в частности:
- фотоаппарат + действие (купить, заказать, с доставкой по РФ);
- фотоаппарат + стоимость (недорого, дешево, по акции, до 10 тыс., до 50 тыс.);
- фотоаппарат + марка;
- фотоаппарат + марка + модель;
- фотоаппарат + характеристика (64 гб, с nfc, 12 дюймов, с двумя симками);
- фотоаппарат + еще какой-то запрос (легкий, в качестве подарка).
Определив маски запросов, вы:
- Грамотно распределите посадочные страницы на сайте по категориям и характеристикам товаров.
- Разработаете страницы под популярные поисковые запросы (например, недорогой фотоаппарат).
- Растиражируете выбранные маски запросов на все остальные группы товаров.
- Сделаете шаблон для сбора семантического ядра.
На этой ступени мы не советуем сильно акцентировать внимание на частотности запроса. В список можете включать любые непустые фразы (с частотой от 1), связанные с вашим бизнес-проектом
При помощи каких фраз вы продвигаете и рекламируете свой товар, дело второе. На данном этапе главная задача – сбор полноценного семантического ядра.
RushAnalytics
Программа Rush Analytics помогает сделать сбор запросов из левой колонки Wordstat более автоматизированным с последующей загрузкой данных в таблицу Excel.
В нашем примере нужно лишь запустить сбор ключей по запросам «фотоаппарат». Но есть одна важная деталь. Wordstat по умолчанию отдает всего 41 страницу с результатами. Как вы понимаете, все запросы по такой схеме получить не удастся. Для обхода ограничения необходимо воспользоваться методом сбора частотности для запросов заданной длины (до 7 слов).
Для этого следует добавить запросы в Wordstat таким образом (обязательно нужны кавычки):
- «фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат»;
- «фотоаппарат фотоаппарат фотоаппарат, фотоаппарат»;
- и так далее – до 7 слов.
Этот метод поможет в сборе максимального количества запросов по вашей теме.
Spywords.ru
Программа spywords.ru дает возможность несколько облегчить себе задачу и собрать семантическое ядро не с нуля, а с помощью сайтов-конкурентов.
Принцип работы предельно прост: нужно выбрать 3–4 лидера в вашей отрасли и собрать все фразы, по которым их ранжируют поисковики в пределах Топ-100.
Конечно, так вы, скорее всего, не соберете полноценную семантику. Но с большой долей вероятности охватите процентов 60, и для начала этого достаточно.